大模型在处理长文本时“内存焦虑”有望成为历史。近日,总部位于东京的AI初创公司Sakana AI发布了两项突破性技术:Text-to-LoRA (T2L) 和 Doc-to-LoRA (D2L)。这两项技术通过创新的“超网络”架构,让大模型无需重新训练,就能在不到一秒的时间内“吞下”超长文档或学会新任务。

长期以来,AI开发者一直面临两难选择:是把长文档塞进对话框(导致反应变慢且极度耗内存),还是花大价钱对模型进行微调。Sakana AI给出了第三种方案——通过“一次性付费”的预训练,生成极小的权重插件(LoRA),实现低成本、高效率的模型适配。
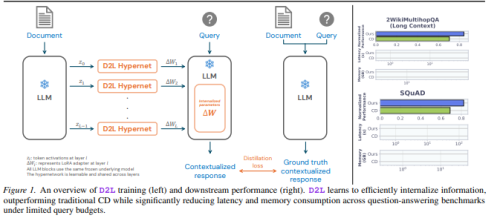
Doc-to-LoRA:12GB内存需求降至50MB
这是本次发布中最令人惊叹的技术。传统方式处理12.8万Token(约十万字)的文档时,模型需要占用超过12GB的显存来记录信息。而使用D2L技术,模型能将这些信息直接“消化”进不到50MB的插件中。
-
速度惊人:传统技术消化文档需要40到100秒,而D2L仅需不足1秒。
-
打破上限:它让模型能够处理比原生窗口长4倍的文本,且在“大海捞针”测试中保持了近乎完美的准确率。
Text-to-LoRA:用大白话“定制”AI
Text-to-LoRA则让模型变得更加听话。用户只需要用自然语言描述一个任务(比如“帮我解决复杂的数学竞赛题”),系统就能自动生成一个专属的性能增强插件。实验证明,这种方式生成的适配器在数学和逻辑推理任务中,表现甚至超过了专门针对该任务训练的独立模型。
跨界神技:让文字模型也能“看图”
研究人员还发现了一个意外惊喜:D2L具备强大的跨模态能力。通过将视觉信息映射到纯文字模型的参数中,一个从未见过图片的文字模型,竟然能以75.03%的准确率对图像进行分类。
Sakana AI的这一系列成果,不仅极大降低了个人和企业定制私有AI模型的门槛,也为实现更轻量、更智能的通用人工智能(AGI)开辟了新路径。
论文:https://arxiv.org/pdf/2602.15902