一台机器人拿起螺丝刀并不难,难的是让它在几秒钟内,精准地把刀头对准一枚细小的螺丝。
这不是未来世界的科幻场景,而是今天机器人操作中最现实、也最棘手的问题。
当前,VLA模型在叠衣服、冲泡咖啡、制作烤奶酪三明治这类多样化任务中已经表现出令人印象深刻的通用能力。但真正走进工厂、实验室,甚至家庭,人们很快发现——通用能力并不等于好用。
原因很简单:真正实用的物理操作还需要精度、灵巧性和速度。而VLA模型在执行“最后一毫米”的高精度操作时,往往会变得犹豫不决、动作迟缓,甚至反复失败。这是为什么呢?因为高精度操作天然对微小误差极度敏感。而这类误差,仅靠专家示范数据很难覆盖。示范数据能教会机器人“怎么做”,却很难教会它“怎么做得又快又准”。
于是,一个自然的思路浮出水面:让机器人在实践中自己学。这正是强化学习的强项。
但问题又来了。
现实中的机器人学习,每一轮尝试都要耗费时间,每一次失败都伴随着设备的磨损。理想情况下,我们希望机器人能在数小时甚至数分钟内,完成对某一关键技能的优化。然而,直接对整个VLA模型进行强化学习微调,计算成本高、样本效率低,根本不现实。
而如果用传统的强化学习方法只训练一个小模型,虽然速度快,但VLA那强大的泛化能力就白白牺牲了。
这就陷入了一个两难:既要VLA的泛化能力,又要在线强化学习的速度和样本效率。
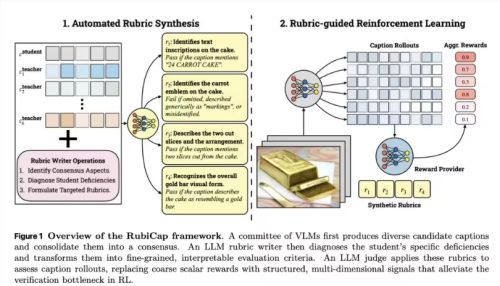
近日,Physical Intelligence(PI)团队在最新研究论文《RL Token: Bootstrapping Online RL with Vision-Language-Action Models》中,提出了 RL Token(RLT)方法。该方法通过构建 VLA 与轻量级强化学习之间的紧凑接口,仅需数小时真实交互数据,即可让机器人完成精密操作的在线优化,有效解决了通用模型难以兼顾泛化性与精确性的行业痛点,为机器人灵巧操作提供了全新技术路径。
一、RL Token 实现方案
RL Token(RLT)的核心设计理念,是冻结VLA模型主体,通过紧凑表征接口,用轻量级网络完成在线强化学习微调,实现泛化能力与精密优化的兼顾。整套方案无需定制化开发,可直接对接预训练 VLA模型,快速适配各类精密操作任务。
RL Token工作机制(PI论文,见参考资料)
1. RL Token 的生成机制
RL Token是VLA 与轻量级强化学习网络之间的紧凑信息接口,通过添加一个编解码Transformer对 VLA 模型进行适配来实现:
编码器负责将VLA 的高维内部表征压缩为低维向量,即 RL Token,浓缩任务核心信息(包括视觉感知、语义理解与动作先验等);
解码器通过重构VLA原始嵌入,确保RL Token保留完整的任务关键信息,形成信息瓶颈,避免有效特征丢失。
训练完成后,冻结VLA 参数,RL Token 作为轻量级Actor-Critic 网络的状态输入,让小型网络也能利用VLA的丰富感知知识,实现高效强化学习。
2. 轻量级强化学习设计基于 RL Token,方案采用样本高效的 off-policy Actor-Critic 在线强化学习算法,仅训练轻量级策略头(Actor)与价值头(Critic),可直接在机器人端本地运行,每秒完成数百次参数更新,实现实时策略优化。
为保证训练稳定性与效率,方案在三大关键设计上进行了如下优化调整:
1)动作空间对齐
强化学习策略直接预测动作块(Action Chunks),与底层 VLA 的动作结构保持完全一致,而非在单步控制层面逐帧执行。通过优化连续动作序列,使在线策略能够有效调整任务中关键的时间扩展性运动模式,满足精密操作对时序一致性的需求。
2)正则化约束锚定行为
策略网络(Actor)将 VLA 预测的动作作为输入,学习对参考动作进行修正而非替代。在策略更新中引入朝向参考动作的正则化约束,约束 Actor网络贴近 VLA 的参考动作:
当VLA 行为已较为合理时,动作与VLA一致,训练稳定;
当动作偏离VLA 时,约束作用增强,引导网络贴近合理动作;
仅当Critic 判定偏离能获得更高奖励时,才允许有限探索,避免无效试错。
同时,为防止策略在训练初期单纯复制VLA 动作,引入参考动作随机丢弃机制(reference-action dropout),强制策略网络维持一条独立的动作生成路径,充分利用先验知识的同时保留自身优化能力。
3)可选的人工干预融合
方案可选择性地将人工干预信号直接融入强化学习更新过程:当机器人出现停滞或执行错误时,人工修正信号可被回传至训练流程,进一步提升策略的鲁棒性与任务适应性。
上述设计使在线强化学习成为一套可直接附加于预训练 VLA 的通用方案,无需针对具体任务进行工程化改造,即可实现稳定、高效的实时策略优化。
3. 端到端落地流程
整套流程将在线强化学习转化为VLA行为的局部精调,而非无约束探索,完美平衡了效率、稳定性与性能。
RL Token 的实际应用分为两步,流程简洁高效:
VLA 适配阶段:在少量任务专属演示数据上对VLA 进行微调。这样做有两个目的:一是提高 VLA 在目标任务上的初始执行能力;二是让它能够输出一个专门用于强化学习的特征(RL Token),供后续训练使用。
在线RL 优化阶段:冻结VLA 参数,并在线训练轻量级的Actor与Critic 网络。网络以 RL Token 表征和 VLA 参考动作作为条件输入,并对学习到的策略施加正则化约束,使其与 VLA 模型保持相近。
这套方法不是让机器人在黑暗中盲目摸索(无约束搜索),而是让它在已经具备一定操作能力的预训练模型基础上,仅进行局部微调。它只训练两个轻量级的小网络,因此运行速度快,同时充分利用了预训练模型已有的理解能力和操作经验,做到了“站在巨人肩膀上”进行高效学习。
RL Token的提取(PI论文,见参考资料)
二、实验验证
为全面验证RLT(RL Token 架构)在高精密操作任务中的有效性,研究人员在四项兼具精度与速度要求的亚毫米级任务上开展了系统实验,包括螺丝安装 (用电动螺丝刀将 M3 螺丝拧入螺纹孔)、扎带紧固、以太网接头插接和充电器插入。实验结果表明,该方案在任务成功率与执行速度上实现了双重突破,并展现出卓越的样本效率与泛化能力。
1. 实验设置
每项任务均包含抓取、重定位与对准环节,总时长为 30-120 秒(控制频率 50Hz,对应约 1500-6000 个控制步)。针对每项任务,研究人员划定了关键阶段——即插入、紧固或旋转环节,该阶段精度要求最高,也是基础 VLA 模型最常出现卡顿或执行失败的环节。关键阶段的时长通常为 5-20 秒(对应 250-1000 个控制步)。
强化学习策略的输入包括:RL Token(由两路腕部相机图像与一路基座相机图像生成),以及额外的本体感受状态。根据任务不同,辅助状态信息有所差异:螺丝安装任务中辅助状态为关节位置;扎带紧固、以太网接头插接、充电器插接任务中,辅助状态为末端执行器位姿。
实验采用π0.6 作为基础VLA模型,机器人的控制频率为50Hz。单时间步动作空间维度为14 维,对应强化学习Actor网络的分块动作维度为140维。
2. 实验结果
1)在线强化学习相较基础VLA策略存在性能提升
在两种设置下评估本方法:隔离关键阶段的受控设置,以及要求强化学习策略具备更强鲁棒性的全任务设置。在线强化学习在两种设置下均能提升基础模型的成功率与执行速度。
在受控设置中,RLT 对四项任务的关键阶段均实现稳定提升。即便在基础策略已具备良好可靠性的相对简单任务(充电器插接、以太网接头插接)中,RLT 学到的策略在关键阶段的执行速度提升约3倍。在难度更高的扎带紧固与螺丝安装任务中,成功率的提升更为显著。
在全任务评估中,由于任务前期环节(抓取、抬升物体等)带来误差累积,整体成功率有所下降,但RLT 仍使螺丝安装任务成功率提升40%,扎带紧固任务成功率提升60%。
全任务与关键阶段受控设置任务评估(PI论文,见参考资料)
备注:1)ScrewDriver:螺丝安装 2)Zip Tie:扎带紧固 3)Ethernet:以太网接头插接 4)Charger:充电器插入
2)相较于基线方法,RLT 带来吞吐率的显著提升
在以太网接头插接任务中,将RLT 与四种基线方法进行对比:
HIL-SERL 与 PLD:均为单步在线强化学习方法,在这一跨数百步、采用稀疏奖励的任务上无法有效学习。若无动作分块,任务时程极长,价值函数更新难以有效传导稀疏奖励信号。
DAgger 与 DSRL:可达到与 RLT 相近的成功率,但在速度提升上效果远弱于 RLT。DAgger 属于模仿学习方法,执行速度受限于人类演示与干预的速度;DSRL 是一种将策略严格约束在基础VLA 附近的强化学习方法,虽能保证训练稳定,但性能提升潜力相对有限。
RLT与其他强化学习算法的对比(PI论文,见参考资料)
备注:将RLT 与近期强化学习相关文献中的多种基线方法进行对比。仅采用单步动作而非动作块的方法(HIL-SERL、PLD)表现较差。DSRL 虽能实现较高的成功率,但在任务吞吐率上显著落后于 RLT。
3)RL Token、动作块、BC 正则项、参考动作直通四项组件缺一不可
实验通过消融测试验证RL Token、动作块、BC 正则项、参考动作直通四项设计的核心价值,任一组件缺失均会导致性能明显下降:
用ResNet-10 编码器替代 RL Token 会使吞吐率下降50%,证明本文提出的Token编码了与操作任务相关的结构信息,这是在标准计算机视觉任务上训练的通用编码器无法提供的。
将动作块(C=10)替换为单步动作,会大幅拉长任务的有效时程,因为价值函数需要在更长的序列上完成信用分配,同时也会导致基于RL Token的方法无法可行运行。在实际实验中,单步变体的性能无法稳定达到基础策略水平。
移除BC正则项(β=0)带来单次最大的性能下跌,因为这会迫使Actor网络仅依靠Q函数的梯度,在完整动作空间中进行探索。
移除参考动作直通会减慢学习速度,导致早期探索偏移,偶尔出现退化行为。尽管在该简单任务上,该消融组最终能达到RLT 的性能,但在训练过程中失败次数更多。
以太网接头插接任务训练过程中不同阶段的吞吐量(PI论文,见参考资料)
备注:1)w/o BC Regularizer:无BC正则项 2)w/o Chunk:无动作分块 3)w/o RL Token : 无 RL Token 4)w/o Pass-Through:无参考动作直通
消融研究表明:本方法的各个组成部分均对实现优异性能至关重要,且完整系统的学习速度最快,最终性能表现最佳。值得注意的是,仅在任务关键部分消耗5分钟数据后,RLT的性能就超越了替代策略(整个实验时长约 40 分钟)。将参考动作从Actor网络输入中移除(“无直通机制” 配置)虽仍能达到最优的最终性能,但代价是学习速度变慢,且在整个训练过程中出现的失败次数显著增多。
以太网插接任务训练过程中的成功率评估(PI论文,见参考资料)
在以太网接头插接任务中,RLT 能够快速达到与VLA策略相当的成功率,同时提升任务吞吐率。若不采用参考动作直通机制,或不使用 RL Token,均会导致模型学习速度变慢。
4)RLT产生超越人类演示的高效行为
实验结果显示:在线强化学习使机器人的任务执行方式发生了根本性变化。
针对以太网插接任务的关键阶段,研究人员可视化呈现了人类遥操作演示、基础VLA模型与RLT策略的速度分布(如上图所示):
基础VLA模型在接近接触目标时,常表现出 “试探” 行为:靠近目标、小幅回撤、重新调整,而后再次尝试 —— 有时需多次循环此类尝试才能成功。
RLT策略会直接靠近接口,并以流畅的动作完成接头插接。即便首次尝试失败,RLT也会施加一定压力并轻微摆动接头,利用机械柔顺性完成更快插接。该行为并未出现在演示数据中,完全源于在线探索,这表明该方法能够超越对人类策略的简单模仿。
三、未来展望
具身智能模型的能力迭代通常遵循一条渐进的技术路径:首先通过大规模预训练,构建通用的感知与基础动作能力,为后续优化提供稳固的模型基座;随后在真实场景部署中,利用任务特定的交互数据对模型进行局部微调,提升关键动作的精度与稳定性;在此基础上,结合人类反馈与强化学习,进一步增强模型在复杂任务中的高层推理与决策能力。
RL Token 正是这一路径中第二阶段的核心实现方法之一 —— 它作为连接 VLA 大模型与在线强化学习的桥梁,将在线 RL 转化为对 VLA 高潜力行为的局部精调,而非无约束探索,从而实现快速高效的学习。在当前方案中,还可以选择性引入人工干预,当机器人执行受阻或出现操作偏差时,通过人工修正信号辅助策略更新,进一步保障训练稳定性。
未来,结合奖励模型、进度预测等技术,有望实现完全自主的强化学习优化流程—— 这恰与路径的第三阶段(基于人类反馈的强化学习(RLHF))相呼应,使机器人无需人工介入即可持续自我进化。当模型能够通过真实场景的持续交互,打通 “预训练 — 场景微调 — 人类反馈优化” 这一闭环时,其在实际任务中的表现将实现持续迭代与稳定提升。
RL Token 不仅是一项重要技术方法创新,更是推动机器人从 “被动执行指令” 向在线自主优化、持续自适应演进的关键技术支撑。通过让通用机器人大模型具备高效在线自优化能力,该方案显著提升了机器人在精细操作场景下的精度、效率与泛化适应性,为智能制造、精密装配等领域的自动化升级提供了可行路径。
原文标题 : RL Token:破解 VLA “最后一厘米”精度难题,在线强化学习实现机器人精准操控