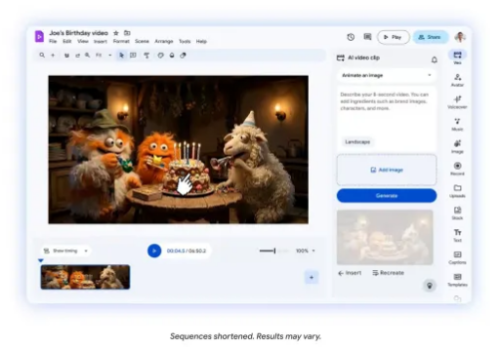
谷歌于4月2日宣布为其企业级视频创作应用 Vids 引入重大升级,通过集成 Veo3.1视频生成模型与自然语言交互技术,实现从静态生成向动态“指令控制”的跨越。 此次更新的核心在于赋予 AI 虚拟形象更强的交互能力,用户仅需输入简单的文字提示,即可指挥形象在场景中完成与产品、道具或设备的特定互动,且能在动态输出中保持角色视觉的一致性。
此外,Vids 进一步整合了多模态能力,在近期加入Lyria3系列音频模型的基础上,Veo3.1的接入支持生成8秒视频片段,并向普通用户及企业高级版账户分别提供每月10次至1000次不等的生成配额。

为打通工作流闭环,Google Vids新增了直接导出至 YouTube 的功能,并配合全新的 Chrome 录屏扩展程序,构建了从素材捕获到成品分发的全链路。
与此同时,人工智能领域的竞争态势正持续升级,微软于同日发布了 MAI 系列三款基础模型,涵盖25种语言的语音转录、音频生成及视频生成能力,旨在通过更低的成本门槛挑战谷歌与 OpenAI 的市场地位。
谷歌自2024年推出 Vids 以来,已迅速迭代了3D 卡通形象及多国语言支持。这种基于提示词的精细化控制功能,标志着 AI 视频工具正从简单的内容生成转向更具专业深度的自动化导演阶段,将进一步重塑企业内容生产的成本结构与创意边界。