作者:liuxjerry 出品:具身纪元

一个让人困惑的现象
你对机器人说:把杯子拿过来。
它听懂了。
它知道杯子是什么,也知道杯子在哪里。
它甚至已经在脑海里规划好了一条看似完美的路径。
但真正伸手去拿的那一刻,动作却常常偏离规划。
为什么会这样?
原因就在一个被长期忽视的问题里:机器人一直在把语言和图片翻译成动作。
被困在翻译过程中的机器人
如果你让一个只会说中文的人,先用英文思考问题,然后再把答案翻译成中文说出来。
这个过程会发生什么?
信息会在翻译中丢失。
语义会在转换中扭曲。
原本流畅的思维,会变得磕磕绊绊。
传统的机器人系统,就陷在这样一个翻译困境里。
它们用视觉和语言来理解世界,然后试图把这些理解翻译成动作。高层模型输出的是抽象的语义信号,比如把碗放进洗碗机这个任务,会被理解成一系列语言描述或视觉预测。但到了真正执行的时候,控制系统拿到的是这些间接的、抽象的信号,它必须再次翻译,才能转化成机械臂的具体动作。
这就是学术界所说的语义-运动鸿沟(Semantic-Actuation Gap)。
这个鸿沟有多大?
智元的GO-1已经是一个里程碑式的突破。它通过创新的ViLLA架构,首次实现了视觉-语言-动作的统一建模,让机器人学会了理解。它能看懂指令,能识别场景,能规划任务。
但当系统进入更复杂的真实环境后,问题逐渐显现。
机器人在整理厨房时,知道应该先把碗碟从水池里拿出来,然后放进洗碗机。理论上这个规划完美无缺。但实际执行时,可能因为视觉误差抓偏了碗的边缘,或者在转身时手臂轨迹偏离了预设路径,最终导致碗碟滑落。
规划没问题。
执行出了错。
问题就出在从规划到执行之间的那道鸿沟。
在执行阶段,控制模块往往会绕过规划信号,直接根据视觉信息生成动作。这导致长程任务误差累积,动作偏离规划,系统的稳定性下降。
这时候,一个更本质的问题浮现出来:
为什么机器人要用视觉和语言来思考动作?
思考的语言决定了执行的质量
人类是怎么学会复杂动作的?
倒水之前,你不会用语言告诉自己水流的路径。
你会在内部形成一个清晰的动作过程,然后自然展开。
这个过程的关键在于:思考本身就发生在动作空间里。
没有翻译。
没有转换。
想法和动作,用的是同一种语言。

三种思考范式对比:语言CoT、视觉CoT、动作CoT(ACoT)
今天,智元机器人正式发布新一代VLA基座大模型Genie Operator-2(以下简称GO-2)。它的核心洞察正是如此:让机器人直接用动作语言思考。

智元GO-2的动作CoT(ACoT)
这个想法听起来简单,但实现起来极其困难。
因为动作空间和语言空间、视觉空间完全不同。语言是离散的符号,视觉是连续的像素,而动作是高维的、时序的、物理约束的轨迹。
如何让模型在动作空间中进行推理?
如何生成可执行的动作规划?
如何确保规划在真实环境中被稳定执行?
GO-2给出的答案,是一套完整的架构创新。

动作思维链:让机器人学会用动作思考
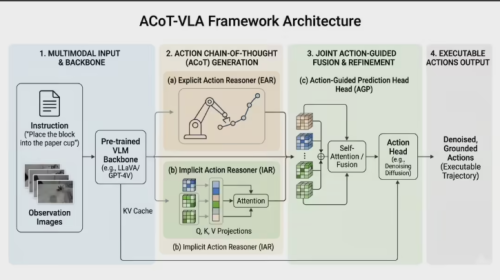
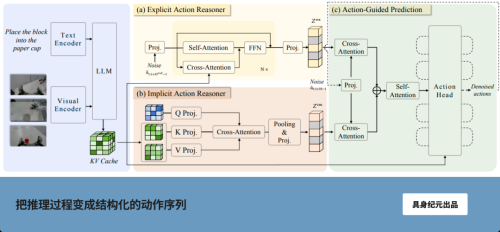
GO-2引入了一个全新的概念:动作思维链(Action Chain-of-Thought,简称ACoT)。
动作思维链
这个概念的核心,是把推理过程本身,变成一个结构化的动作序列。
传统方法是:感知输入 → 直接生成控制信号。
思考和执行被压缩在同一个瞬间完成,模型既要理解任务,又要完成精细控制,往往难以兼顾。
ACoT的做法是:感知输入 → 生成高层动作序列 → 基于序列生成控制信号。
模型不会立即输出控制信号,而会先生成一段高层动作序列,作为任务的整体规划。这一序列描述了行为的方向、结构以及执行路径,是一种可以直接被执行系统理解的中间表示。

ACoT-VLA架构
但光有高层规划还不够。
真实世界充满了不确定性。桌面高度可能和预期不一致,物体摩擦特性可能发生变化,环境中可能出现意外障碍。
如果只是简单地执行预设的动作序列,机器人很快就会偏离轨道。
这就需要第二个关键创新:异步双系统架构。
慢思考与快执行的完美配合
GO-2把动作的规划和执行也拆分为两个不同节奏的模块。
慢系统负责思考。
它以较低频率运行,生成结构化的高层动作序列。这些动作不会直接展开为控制信号,而是以逐步细化的方式持续提供指导。从宏观动作到子动作,再到更细粒度的行为片段,形成一个具有层次结构的动作表示。
快系统负责执行。
它以更高频率运行,持续接收来自慢系统的动作规划,并结合当前的视觉观测生成具体控制信号。
关键在于,执行过程中会持续进行局部修正与动态调整。
当桌面高度与预期不一致时,系统会自动调整手臂的下探幅度。
当物体摩擦特性发生变化时,会实时调整抓取力度。
这种连续修正,使执行始终贴合规划,而非逐步偏离。
这个设计的精妙之处在于:规划提供方向,执行保持灵活。
就像开车时,你脑海中有一条大致路线(慢系统),但双手会根据路况实时调整方向盘(快系统)。两个系统各司其职,又紧密配合。

ACoT-VLA架构
为了让这套系统真正稳定工作,GO-2还引入了一个巧妙的训练机制:带噪声的强制教学。
在训练执行模块时,系统会使用真实的高层动作序列作为条件,但同时加入一定扰动,模拟规划误差。
这使得模型能够在接近正确但不完美的规划条件下依然保持稳定执行。
就像学开车时,教练会故意制造一些小状况,让你学会应对意外。
这种训练方式,让机器人在实际部署中具备了更强的鲁棒性。
性能表现:刷新行业SOTA
当思考与执行真正被打通,带来的改变不仅仅是指标上的提升,而是系统行为方式的跃迁。

GO-2在多个主流具身智能基准测试中取得了全面SOTA。
在LIBERO基准测试中,GO-2在Spatial、Object、Goal与Long四类任务上均排名第一,平均成功率达到98.5%。
在LIBERO-Plus基准测试中,这个测试包含相机、光照、背景和噪声等多种环境扰动,GO-2零样本测试取得86.6%平均成功率,显著超过现有方法。
在VLABench的跨类别与纹理泛化测试中,GO-2平均达到47.4,特别是纹理泛化任务上显著优于其他方法。
最关键的是Genie Sim 3.0 Benchmark的Sim-to-Real测试。这个测试评估的是模型从仿真到真实世界的迁移能力。GO-2在仅使用仿真数据训练的前提下,在真实环境测试中取得了82.9%的平均成功率,显著优于π0.5的77.5%。
GO-2在多个基准测试中的性能对比
这些数字背后,是一个根本性的转变:
机器人从边看边做,变成了想清楚动作以后再做。
从动作的即时反应,变成了动作的结构化执行。
从翻译出动作的范式,进入了动作原生范式。
从翻译到原生:一场思考方式的革命
GO-2的意义,远不止于一个模型的性能提升。
它揭示了一个更深层的规律:智能系统的能力边界,往往取决于它用什么方式思考。
过去几十年,AI领域一直在做翻译的工作。
把图像翻译成文字。
把文字翻译成动作。
把一种模态的信息,翻译成另一种模态的输出。
这个范式在很多领域都很成功。图像识别、自然语言处理、语音识别,都是基于这个思路。
但在具身智能领域,翻译范式遇到了天花板。
因为动作本身就是一种独特的语言。
它有自己的语法(物理约束)。
它有自己的语义(运动学意义)。
它有自己的表达方式(轨迹序列)。
当你试图用另一种语言来描述动作,然后再翻译回来,信息必然会丢失。
GO-2开启的原生范式,是让系统直接用动作语言思考。
不需要翻译。
不需要转换。
思考和执行,用的是同一种语言。
这个转变的启示,不仅限于机器人领域。
在多模态大模型的发展中,我们也看到了类似的趋势。早期的多模态模型,是把图像编码成文本token,然后用语言模型处理。现在越来越多的模型,开始探索原生的多模态表示,让不同模态在统一的空间中直接交互。
在具身智能的下一步发展中,这个趋势会更加明显。
规模化落地:从模型能力到真实世界部署
在GO-2的基础上,智元进一步打通了模型能力与真实场景部署之间的闭环。通过“基座模型+分布式强化学习”的协同范式,让机器人在真实环境中持续学习、持续进化。
依托Genie Studio开发平台,系统构建了面向真实世界的闭环学习能力:
通过云端与多机器人协同,不断采集交互数据并进行在线后训练,使模型在真实环境中持续优化,而不是依赖离线的数据或仿真。
每一次执行,都是一次数据积累;每一次反馈,都是一次能力提升。
通过这一“预训练+后训练+数据闭环”的体系,GO-2就不只是一款训练好的静态模型了,它能够在真实世界中持续学习、不断进化。
一个完整的智能闭环系统,正在形成。
知行合一的新高度
具身智能的终极追求,是知行合一。
这四个字,在中国哲学中有着深刻的含义。
知,是认识世界。
行,是作用于世界。
合一,是两者之间没有鸿沟。
GO-2所做的,正是为具身智能打造真正会思考、能稳定执行的通用大脑。
从GO-1到GO-2,智元完成了一次关键跃迁。
从理解世界,到真正作用于世界。
从可以成功,到稳定完成。
从翻译范式,到动作原生范式。
这个跃迁的核心,是找到了正确的思考方式。
让机器人用动作原生来进行思考,就像让人类用母语思考一样自然。
没有翻译的损耗。
没有转换的延迟。
想法和行动,直接连通。
这才是真正的知行合一。
当机器人开始用动作原生的方式思考,具身智能的大门,才真正打开。