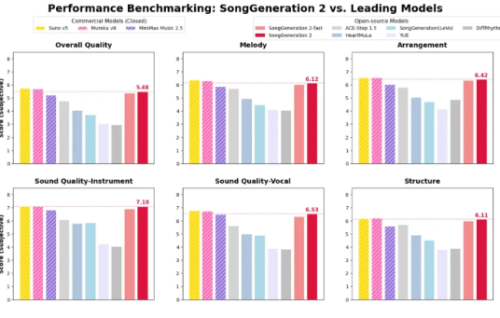
AI 音乐赛道在2026年初迎来了又一次震撼余震。3月9日,由腾讯与清华大学人机语音交互实验室联合研发的音乐基础模型 SongGeneration2 正式面世。这款模型不仅在技术架构上实现了质的飞跃,更在多个核心维度上直接“断崖式领先”目前主流的开源模型,甚至在整体质量上完成了对顶级商业模型的正面硬刚。

三大突破:让 AI 音乐不再有“塑料感”
SongGeneration2的核心优越性源于其底层架构的全面升级,主要解决了过往 AI 音乐的三大痛点:
-
高音乐性: 不同于简单的旋律叠加,该模型能处理复杂的多轨编曲,空间层次感极强。
-
高歌词准确性: 咬字不清、幻觉跑调成了过去式。其音素错误率(PER)仅为 8.55%,这一数据显著优于顶级商业模型Suno v5(12.4%),仅次于MiniMax2.5。
-
极强可控性: 无论是文本描述还是音频提示,它都能精准遵循,深度定制风格与情绪。

“双核”驱动:LLM 与扩散模型的梦幻联动
在架构设计上,SongGeneration2采用了创新的混合式 LLM-扩散架构:
-
作曲大脑(LeLM): 负责规划全局结构与演唱细节,解决“怎么唱”的问题。
-
高保真渲染器(Diffusion): 在语言模型的指导下,合成极其复杂的声学细节。
-
分层表征: 首创混合表征与多轨表征并行建模,兼顾了旋律的稳定性与音质的细腻度。
真开源、低门槛:普通电脑也能“写歌”
最令开发者振奋的是,腾讯此次展现了极大的开源诚意。拥有4B 参数的 SongGeneration-v2-large 模型已正式开源,支持中英等多语种生成。令人惊讶的是,它在配备 22GB 显存 的消费级硬件上即可流畅运行,实现了本地化、私密化创作的可能。
为了让用户即刻体验,项目组还在 HuggingFace 推出了 SongGeneration-v2-Fast 版本,牺牲极小部分音质以换取极速生成——一分钟内即可诞生一首完整单曲。
从SongGeneration2的表现来看,AI 音乐已经从“极客玩具”正式跨入“商业级应用”的大门。随着未来支持12G 显存的 Medium 模型及自动化评估框架的开源,全民“作曲家”的时代或许真的不再遥远。