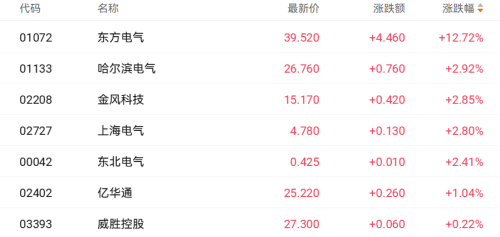
作者:陈康成 出品:机器觉醒时代
具身智能在数据层面的核心瓶颈,本质上是高质量物理交互数据的极度稀缺。3月16日,在GTC 2026大会上,王兴兴发表题为“如何迈过具身智能的ChatGPT时刻”的演讲,指出行业要迈过这一关键节点,至少还需共同攻克三大核心问题。其中一项便是如何提升模型对多元数据的利用效率,增强知识迁移能力。
这意味着,未来突破具身智能数据瓶颈的关键,应聚焦于挖掘模型对互联网数据、合成数据以及真机数据等多元化数据的使用效率,进而从根本上降低具身智能对真机数据的依赖。
目前,行业内已在真机交互数据、合成数据与互联网视频数据三大方向,均涌现出一批具备落地潜力的探索路线与技术实践。
一、真机数据
真机数据采集的核心瓶颈,在于采集效率低下、部署成本高昂。UMI(Unified Manipulation Interface)是当前缓解这一问题、且在行业内认可度较高的轻量化方案,尤其适合低成本、规模化获取高质量真机交互数据的场景。
UMI 由斯坦福大学与谷歌团队联合提出,是一套面向机器人操作的统一化示教接口。其核心思路是通过轻量化手持传感装置(简易末端执行器、消费级交互硬件等)实现人类示教,在完成精细操作演示的同时,同步采集视觉观测、末端运动轨迹与机器人状态信息,最终形成可直接用于模仿学习与强化学习的高质量真机交互数据集。
与传统遥操作不同,UMI 更强调示教轨迹的轻量化采集与跨机型复用,不追求实时高精度远程操控,而是专注于高效生成可泛化的机器人学习数据。
目前UMI方案在海内外均有方案落地,典型代表企业如下:
海外企业:以Generalist AI、Sunday Robotics、Weave Robotics为代表,聚焦具身智能数据基建与轻量化示教场景,推动UMI技术的工程化落地。
国内企业:鹿明机器人、简智新创、松灵机器人、穹彻智能、BeingBeyond(智在无界)等厂商均已布局相关方案,结合本土应用场景完成UMI技术的商业化适配与场景拓展。
二、合成数据
对于合成数据而言,核心瓶颈之一仍是Sim2Real Gap。当前主流解决方案主要沿两条互补路线推进:
1. 构建 Sim2Real2Sim 双向闭环,系统性弥合虚实差异
传统Sim2Real 是单向迁移,模型在仿真中训练后直接部署至现实世界,效果往往受限于环境偏差与物理建模误差。更高效的范式是构建 Sim2Real2Sim 闭环:
Sim2Real(仿真→真实:部署真机执行任务):把优化后的模型部署到真机,在真实世界执行任务。
Real2Sim(真实→仿真: 真实数据反哺仿真):把真机在真实世界执行中遇到的失败案例、传感器噪声、物体物理属性(摩擦、质量、刚度)等运行数据回传到仿真系统,校准仿真的物理参数、场景分布、域随机化策略。
仿真系统根据真实数据,生成更贴近现实、甚至更难的极端场景,让模型在仿真里大量试错、强化学习、策略优化。完成后,模型再次部署至真机。通过这种循环迭代,模型与仿真环境实现协同进化,从根本上缩小域偏移。
另外,实现Sim2Real2Sim这一闭环还依赖两大关键技术:
领域随机化(Domain Randomization):让仿真“包罗万象”,解决泛化。放弃对现实世界的精确拟合,在仿真中主动引入大规模扰动,包括物体参数、摩擦系数、光照、纹理、相机噪声与执行器偏差,使模型学习鲁棒策略而非拟合特定仿真环境,提升在真实世界的泛化能力。
系统辨识(System Identification):让仿真“逼近真实”,解决精度。利用真机交互数据反推现实世界的物理参数与动力学特性,持续校准仿真环境,使其逐步逼近真实物理分布,从源头降低Sim2Real 差异。
以英伟达Omniverse、MuJoCo 为代表的仿真平台已在高保真渲染、软体动力学、流体模拟与精细接触物理上取得显著进展,但当前真正的工程瓶颈在于领域随机化与系统辨识的自动化结合,实现高效、可扩展的虚实对齐。
2. 生成式大模型作为数据生成引擎,驱动自动化训练飞轮
将生成式大模型作为数据与场景生成引擎,可推动具身智能摆脱对有限真实数据与固定仿真场景的依赖,实现训练环境的自主构建与迭代升级。与 VLA 模型聚焦视觉 - 语言 - 动作三模态对齐、学习任务执行策略的技术路径不同,生成式大模型的核心价值,是为机器人打造规模无限、多样性极高、语义与物理双重合理的训练场景,承担虚拟任务设计者与自动化训练引擎的核心角色。
其核心能力具体体现在两个层面:
任务与场景自动生成:大模型可依据机器人的能力短板与真机失败案例,自主生成长尾分布、极端工况与开放环境下的任务场景,覆盖真实数据难以采集的干扰因素、异常状态与复杂操作,大幅扩充训练分布范围,降低对真机实测数据的依赖。
与仿真引擎协同生成物理保真的训练数据:大模型负责语义层面的任务规划、场景布局与逻辑合理性校验,仿真引擎保障物理交互的动力学真实性,二者协同构建可规模化生成的高保真机器人交互数据集。
该技术路径的最终目标,是形成大模型驱动的仿真数据训练飞轮闭环:真实世界的任务难题与失败案例触发场景生成 → 仿真环境完成模型迭代优化 → 优化后模型部署至现实场景 → 新的真实交互经验反向迭代仿真场景分布。
这一范式能够以极低成本预演大量未知物理场景,从根本上缓解真机交互数据稀缺、采集成本高昂的瓶颈。
目前生成式大模型赋能具身智能的技术方案已进入商业化试点阶段,依托大模型场景生成、仿真协同的核心能力,部分企业已实现从仿真训练到真机部署的技术链路验证,国内外企业围绕技术范式形成上下游/ 分层级的差异化布局。
A.国内企业:聚焦数据底座、模型全栈与硬件落地的产业链分工
国内以光轮智能、极佳视界、银河通用、大像机器人等企业为代表,以「数据生成引擎+ 训练飞轮」核心,开展产业链上下游差异化布局:
光轮智能:依托第三方生成式框架,筑牢数据底座
聚焦具身智能上游数据环节,采用NVIDIA GR00T 系列第三方生成式框架,搭配自研物理仿真引擎,借助生成式大模型的场景生成、行为推演能力,批量生产高保真合成数据,提供仿真训练、模型评测全流程服务,为训练飞轮提供核心数据供给。
极佳视界:自研生成式大模型,打通全链路闭环
布局中游模型与全栈技术,核心依托自研GigaWorld 世界模型、GigaBrain 具身基模两大生成式大模型,兼顾外部主流框架协同优化,通过大模型实现虚拟场景生成、多模态仿真协同,完成从模型训练、仿真验证到自研机器人真机部署的全链路飞轮验证。
银河通用:自研数据基建与具身模型,构建虚实融合训练体系
聚焦数据基建与具身大模型自研,打造银河星坊(AstraSynth)合成数据生成平台,依托高精度物理仿真环境,批量生成多场景、多任务合成数据,搭建规模化具身智能数据集。采用“合成仿真数据为主、真机数据为辅”的训练模式,搭配自研GraspVLA抓取大模型等具身模型开展训练,完成策略泛化验证,并将仿真习得能力迁移至自研机器人真机,推进合成数据到真机部署的闭环落地。
大象机器人:借力生成式仿真能力,落地终端真机部署
立足下游硬件落地场景,采用第三方通用生成式仿真框架,承接上游仿真训练成果,将虚拟场景的策略逻辑迁移适配至自研机械臂、人形机器人硬件,补齐训练飞轮「仿真到真机」的终端落地环节。
B.海外企业:分层布局基础设施与应用层落地
海外以Google DeepMind、NVIDIA、Skild AI、Covariant 为代表,形成基础设施层 + 应用层的分层布局,同步支撑全球训练飞轮的技术底座与场景落地:
基础设施层(Google DeepMind、NVIDIA):前者依托自研Genie 系列生成式世界模型,后者通过 Cosmos 世界模型平台 + Isaac Lab 仿真框架,共同为具身智能体提供可规模化生成的交互式虚拟训练环境,夯实训练飞轮的技术底座。
应用层(Skild AI、Covariant):Skild AI 深度集成 NVIDIA Cosmos 与 Isaac Lab,依托合成数据训练具备强泛化能力的通用机器人控制模型 Skild Brain;Covariant 则在其 RFM-1 模型中内嵌生成式世界模型,让机器人通过预演物理交互结果优化决策逻辑,实现训练飞轮在终端应用的价值转化。
三、互联网数据
对于具身智能领域而言,互联网海量公开视频数据是尚未被充分挖掘的高价值数据金矿。该类数据不仅具备规模化优势,更是当前唯一可同时承载时序演化规律、真实物理交互特性、人类示范行为范式与多模态融合信息的数据形态,能够以低成本为具身智能模型注入通用物理先验与人类交互行为常识,是缓解真机交互数据采集稀缺、成本高昂瓶颈的核心补充路径。
其主要落地路径可分为两大维度:
1. 第一人称(Egocentric)视角视频
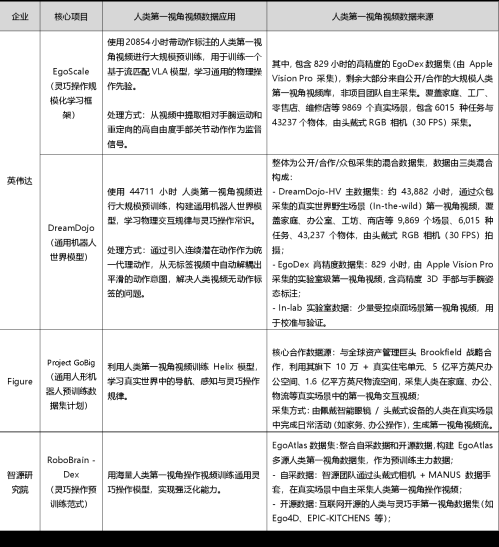
第一视角视频(Egocentric Video),即由人类自身佩戴的采集设备(头戴相机、手持第一视角手机 / 运动相机)拍摄,拍摄视角与感知主体的视线、运动坐标系完全一致,属于自我中心视角数据。
该类数据的核心优势在于:数据的观测视角与机器人端侧相机的感知范式天然匹配,任务意图、执行动作、视觉反馈三者的时序因果关系具备原生对齐性,无需额外做视角转换,能为机器人行为理解、模仿学习提供低成本的弱监督信号,是具身智能学习人类操作逻辑的优质数据源。
然而,其落地瓶颈在于直接复刻人类运动轨迹无法适配机器人真机执行,仍存在两大障碍:其一,机器人与人类在本体结构、运动自由度、力矩输出特性、末端执行器形态上存在本体异构差异,人体运动轨迹不具备直接迁移性;其二,互联网场景下的人类第一视角视频几乎均采用单目摄像机采集,无法输出精确6D 位姿、接触力控、关节力矩等精细操作必需的底层物理信号,单纯轨迹复刻会直接导致真机执行失效、任务失败。
当前行业公认的突破路径,是摒弃轨迹级生硬复刻,转向任务级模仿学习,即从视频中解耦任务意图与关键状态变化规律。例如针对人类颠勺炒菜视频,模型无需复刻人体手臂姿态与运动轨迹,只需拆解提炼“使食材均匀受热、完成空中翻转”的核心物理目标与关键状态节点,再结合机器人自身本体特性,生成可控、可落地的自主运动方案。


人类第一视角视频的应用(机器觉醒时代制图)
2. 第三人称视角视频
以抖音、YouTube 等平台的海量公开视频为代表,是具身大模型大规模通用预训练的核心数据源。这类数据的核心价值在于:覆盖极致丰富的场景、物体、交互方式与环境动态变化,可支撑规模化预训练,为模型注入通用物理先验(重力、摩擦、碰撞、物体刚柔性等规律)、物体可供性(功能属性与交互方式)、环境交互常识与跨场景语义理解能力,构建机器人适配开放世界的基础认知体系。
其核心落地瓶颈在于:存在视角偏移、目标遮挡、动作表征粒度粗糙、无精细化操作时序监督信号、伪相关噪声冗余等问题,无法直接用于精细化操作的端到端模仿学习。当前主流解决方案是通过视觉基础模型完成跨视图几何对齐、视角转换与语义信息提纯,结合弱监督学习范式,为模型注入通用先验知识,而非直接复刻人类动作轨迹。
整体而言,互联网视频数据在具身智能中的应用已形成边界清晰、能力互补的功能分层与协作体系,核心是通过大规模低成本视觉数据,完成从“通用世界认知”到“具身行为对齐”的能力跃迁,整体分为上下两层:
第一层:通用认知预训练层
核心目标:利用可得性最高、覆盖场景最广的互联网视频,构建强泛化的通用视觉认知底座,解决具身智能对世界的“观测与理解”问题。
当前存在两条技术路径,在工程落地中常形成互补:
主流路径——第三人称视频主导的通用表征学习:以海量互联网第三人称视频为核心,通过自监督学习提取物体属性、空间关系与物理交互规律,形成“全局观察世界”的通用视觉表征。其优势在于数据规模与场景泛化性天花板极高;瓶颈在于需通过跨视角对齐机制(如视角重定向、联合嵌入)缩小与机器人第一人称控制之间的表征鸿沟。
前沿路径——第一人称视频主导的具身适配表征学习:直接以大规模第一人称视频(如Ego4D、人类操作视频)进行预训练,观测视角与机器人本体天然对齐,可大幅降低跨视角适配成本,强化视觉特征与操作行为的相关性。其约束在于高质量第一人称操作视频规模有限,且需解决人类与机器人本体结构的域偏移问题。
双路径协同:工程落地中普遍采用“第三人称预训练打底 + 第一人称增量预训练/微调”的互补方案,兼顾场景泛化性与视角对齐性,形成高泛化、强适配的视觉认知底座。
第二层:具身行为对齐层
核心目标:基于预训练的视觉认知底座,采用高质量第一人称操作视频,通过视觉-动作联合表征微调,实现从“被动观察世界”到“主动参与操作”的能力跃迁,解决“视觉信息如何转化为可执行动作”的核心问题。
此类视频大多不直接提供动作标签,当前主流转化路径包括:
逆动力学驱动的动作推断:从视频中提取手-物交互的时序位姿变化,通过预训练的逆动力学模型(在仿真或真机数据上训练获得)映射为机器人可执行的关节动作轨迹。
视觉-语言-动作(VLA)范式的行为先验蒸馏:基于多模态大模型构建“视觉-语言-动作”联合表征空间,将人类操作视频中的时序行为、任务语义与因果逻辑蒸馏为可迁移的通用行为先验,同时实现操作技能迁移与语言指令对齐。
通过上述路径,互联网视频数据完成从“通用世界认知”到“具身操作能力”的全链路价值转化,成为具身智能突破场景泛化瓶颈的核心数据来源。