出品:AMAP CV Lab, Alibaba Group
来源:论文:https://arxiv.org/abs/2602.11236
代码:https://github.com/amap-cvlab/ABot-Manipulation
项目主页:https://amap-cvlab.github.io/ABot-Manipulation
一、直面具身智能的系统性挑战
构建能够适应不同硬件形态的通用机器人智能体是该领域的终极目标。然而,其发展长期受限于三大系统性障碍:
数据异构性壁垒:全球研究机构采用的机器人硬件、数据采集协议和动作表征各不相同,导致数据呈“孤岛化”分布。这种异构性使得大规模、跨平台的联合训练难以实现,阻碍了模型学习普适性技能。
跨形态泛化鸿沟:为特定机器人训练的策略模型,通常难以直接迁移至形态迥异的其他机器人上。这种“一脑一用”的局限性与“一个大脑,多种形态”的理想背道而驰,极大地限制了模型的通用性与应用范围。
学习范式效率瓶颈:许多主流的动作生成模型(如扩散模型)通过预测高维随机噪声来间接生成动作。对于具有明确物理约束和结构性的机器人动作而言,这种学习目标不仅低效,还容易导致生成的动作序列出现抖动和不稳定性。
为系统性地应对上述挑战,高德CV Lab提出了ABot-M0框架。

▲ ABot-M0 框架:一个集数据治理、模型创新和训练策略于一体的综合性解决方案
二、ABot-M0:一套完整的开源技术栈
ABot-M0并非单一模型,而是一套包含三大支柱的集成化框架,旨在从根源上打通从异构数据到统一高效模型策略的全链路。
统一的数据基石 (UniACT-dataset):通过系统化的数据治理流程,我们整合并标准化了全球主流的公开机器人操作数据集,构建了目前非私有领域内规模最大、形态最丰富的机器人操作数据语料。
创新的学习范式 (Action Manifold Learning):我们提出“动作流形假说”,并据此设计了全新的“动作流形学习”(AML)机制。该机制革新了传统生成模型的学习目标,显著提升了模型训练效率和生成策略的稳定性。
灵活的感知架构 (Modular Perception):我们采用了VLM(视觉语言模型)与3D几何感知相融合的双流设计。该设计在不修改骨干网络的前提下,兼顾了模型的语义理解泛化能力与空间操作的精确性。
三、核心技术深度解析
1. UniACT-dataset:构建跨形态、大规模的标准化数据基础
高质量、大规模、标准化的数据是实现通用具身智能的基石。为此,我们精心构建了 UniACT-dataset。

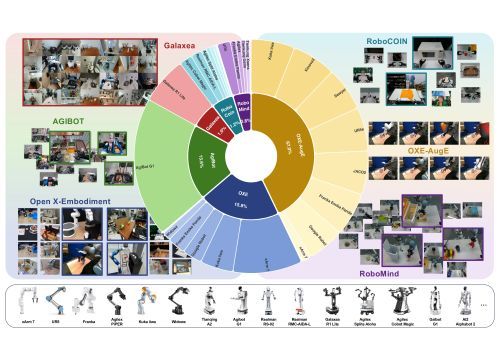
▲ UniACT-dataset 数据标准化与整合流程
前所未有的规模与多样性:我们整合了OXE、OXE-AugE、AgiBot-Beta、RoboCoin、RoboMind、Galaxea等6个主流开源数据集,形成了总计超过 600万条轨迹 和 9500小时 的交互数据,覆盖了20多种不同的机器人形态。
严格的标准化流程:
统一动作表征:所有数据中的动作均被转换为以末端执行器(EEF)为中心的 增量式动作(Delta Actions),其中旋转部分采用更稳定、更连续的 旋转向量(Rotation Vectors) 表示。这套表征体系有效消除了不同机器人在运动学上的差异。
统一任务范式:我们创新性地采用 “填充至双臂”(Pad-to-Dual-Arm) 策略,通过零填充将单臂任务轨迹扩展为双臂格式,使得单一模型能够无缝处理单臂与双臂协同任务,极大地增强了模型的通用性和灵活性。
2. 动作流形学习 (AML):颠覆传统的高效动作生成范式
传统扩散模型通过学习预测高维、无结构的噪声(ϵ-prediction)来生成数据,其学习目标与物理世界中高度结构化的机器人动作之间存在着巨大的语义鸿沟。为此,我们提出 “动作流形假说”(Action Manifold Hypothesis):有效的机器人动作序列并非随机分布于高维空间中,而是存在于一个由物理定律、任务目标和环境约束共同决定的低维、光滑的流形上。

▲ 动作流形学习 (AML) 与传统噪声预测 (ε-prediction) 的对比
基于该假说,我们设计了 动作流形学习(AML) 范式:
革新学习目标:模型不再预测随机噪声,而是直接预测“干净”的完整动作序列(a-prediction)。这一转变将学习过程从漫无目的的“去噪”聚焦到高效的“向可行流形投影”,使学习目标更明确,收敛更迅速。
提升效率与稳定性:结合 DiT (Diffusion Transformer) 架构,AML不仅显著提升了推理速度,更重要的是,通过直接在动作空间进行优化,生成了更平滑、更符合物理规律的动作策略,尤其在处理长序列、高维度(如双臂协同)任务时展现出巨大优势。
3. 双流感知与两阶段训练:融合泛化性与精确性
双流感知融合:
VLM语义流:以 Qwen3-VL 为骨干,为模型提供强大的场景理解与指令遵循能力,是其泛化性能的保障。
3D几何流:通过 即插即用(Plug-and-Play) 的3D模块(如VGGT、Qwen-Image-Edit等),为模型注入精确的空间几何先验知识,有效弥补了标准VLM在精细3D定位能力上的不足。
两阶段训练策略:
第一阶段:大规模预训练:在UniACT-dataset上进行训练,使模型掌握跨任务、跨形态的通用动作先验。
第二阶段:监督式微调(SFT):在特定下游任务上进行微调,注入领域特定的高精度空间知识,从而在保持泛化能力的同时,大幅提升模型在复杂任务上的成功率。
四、实验验证:SOTA性能与卓越的泛化能力
我们在多个行业公认的仿真基准上对ABot-M0进行了全面评估,实验结果充分验证了其卓越的性能与泛化能力。

▲ ABot-M0 在多个基准测试中排名第一
公开榜单登顶:在具身智能VLA公共榜单上,ABot-M0凭借其卓越的性能,已在LIBERO-PLUS零样本泛化和RoboCasa GR1两项关键基准测试中取得排名第一的优异成绩,有力证明了其在复杂任务和泛化能力上的领先地位。
LIBERO & LIBERO-Plus:在考验长程任务能力的 LIBERO 基准上,ABot-M0 取得了 98.6% 的平均成功率。在更具挑战性的零样本泛化测试集 LIBERO-Plus 上,成功率高达 80.5%,显著优于OpenVLA等前沿模型。

▲ LIBERO 基准测试详细评估结果

▲LIBERO-Plus 零样本泛化测试结果对比
RoboCasa & RoboTwin 2.0:在复杂的双臂协同操作基准 RoboCasa GR1 上,ABot-M0 达到了 58.3% 的成功率,验证了AML范式在处理高维动作空间时的优越性。在多任务泛化基准 RoboTwin 2.0 上,模型在场景高度随机化的情况下,仍能达到 81.2% 的成功率。

▲ RoboCasa GR1 双臂协同操作评测表现
同时在GitHub上也更新了最新的 86.1% 的成功率,仍有较大提升空间。

▲ RoboTwin 2.0 在高度随机化场景下的多任务泛化结果
五、赋能社区:开放与协作
ABot-M0 的核心价值不仅在于提供一个高性能模型,更在于贡献了一套 从数据到模型、从架构到训练的完整、透明、可复现的开源解决方案。我们的工作证明,通过对公开资源的深度整合与系统性创新,同样可以构建出性能顶尖、泛化卓越的通用机器人智能体。

▲ ABot-M0 GitHub代码仓库与模型权重已全量开源
为进一步推动开源社区的协同发展,ABot-M0的预训练权重已向社区开放,并可作为starVLA开源代码库中各类VLA模型架构的VLM(视觉语言模型)起点。这一举措旨在降低研究门槛,加速社区在通用机器人策略模型上的探索与创新。

▲starVLA 开源代码库生态示意图,ABot-M0 可作为其VLM起点
我们期待ABot-M0能成为社区研究的重要基石,赋能更多的研究者和开发者,共同推动具身智能技术向前发展,早日实现“一个大脑,驱动万千形态”的宏伟蓝图。