过去两年,如果你问我,判断一家具身智能公司到底“行不行”,最关键的标准是什么?我的回答可能和大多数人一样,都是看它的模型跑分,看机器人在落地场景的成功率有多高。
那个阶段,行业还处于“跑马圈地”的野蛮生长期。一个流畅的抓取、一次丝滑的折叠,就足以让资本市场和围观群众热血沸腾。但到了今天,如果你还在用单一的“成功率”来审视一家公司的核心能力,坦白说,你很可能已经被表象所迷惑了。
因为,具身智能的竞争,已经悄然进入了“深水区”。尤其是3月26日中国信息通信研究院联合40余家单位共同起草的具身智能领域首个行业标准正式发布,该标准为具身智能领域构建了统一基准测试框架,标志着具身智能评测即将迈入“有标可依”的新阶段。

据了解,这项标准聚焦人工智能关键基础技术和具身智能基准测试方法,同时明确了具身智能系统框架和能力要求,将于2026年6月1日正式实施。标准规范了在仿真环境和真实环境下,面向具身智能系统的基准测试框架、方法和指标。标准提出的评测体系支持基础能力、认知推理能力以及全链路闭环能力的测试,覆盖静态仿真测试、动态仿真测试、真实环境测试和组合式测试四种测试方法。
这个“深水区”的标志,就是我们不再满足于问“它能不能做到”,而是开始追问一系列更深刻的问题,它是真理解,还是死记硬背?它能举一反三,适应从未见过的环境吗?它的动作是否符合物理规律,还是仅仅在“演”一段预设的脚本?它进行长序列操作时,会不会在中途“失忆”或“犯傻”?要回答这些问题,靠过去那种“一锤子买卖”式的测试已经远远不够了。
PART 01
为什么“成功率”突然不灵了?
首先,我们必须承认一个残酷的现实,在实验室环境下,堆出来的成功率,正在严重贬值。想象一下,一个学生花了三年时间,只刷一套高考真题,最终考了满分。你能说他是“学神”吗?当然能。但你能说他具备解决所有现实世界问题的能力吗?显然不能。
这就是当前具身智能评测面临的尴尬,许多模型在精心设计的“题库”里表现出色,但一旦进入真实、开放、动态的环境,就像学霸走进了社会大课堂,处处碰壁。
这背后的原因在于,传统评估存在两个致命盲区。
首先是“黑盒”式的评判标准,一个95%的成功率,背后可能隐藏着截然不同的真相。它可能是在同一个桌面、同一个光照、同一个物体下,反复测试了100次的结果。这个模型可能根本不具备哪怕是最基本的泛化能力。而另一个80%成功率的模型,则是在7种不同光照、5种不同干扰物、甚至包括人类故意“使绊子”的极端情况下跑出来的。这两个“分数”能相提并论吗?
其次是“非全即无”的粗暴判断,一个长达20步的复杂任务,模型在前19步都表现得完美无瑕,却在最后一步因为一个微小的失误导致失败。按照传统标准,这整段尝试被标记为“失败”,模型在整个过程中展现出的卓越规划、精准执行和长时记忆能力,被一个冰冷的数字彻底掩盖了。
当一个行业的评估工具开始失效,就意味着它正在呼唤一场新的标准革命。
对于具身智能领域首个行业标准正式发布,专家指出,为确保标准的可操作性,在标准编制过程中,同步建设了配套测试任务库、测试工具和标准测试环境。目前已建设1万多条测试任务库,覆盖工业、家庭、零售、物流等300种任务类型,构建了数据采集和管理、仿真任务生成和指标自动化计算等测试工具。这就意味着对于具身智能的评估标准,将得到进一步的细化。

PART 02
“综合素质评价”的三份“考卷”
在期待6月该标准正式实施的过程中,我们发现,更早之前,无论是国家级机构、顶尖高校还是头部企业,都在推动建立全新的评估范式,尝试搭建一套全方位、多层次的“综合素质评价”体系。
整体来看,国内已经初步形成三类“考卷”,能否从不同维度分别考察模型的不同素养。
第一类“考卷”是EIBench为代表的评估标准。这就像我们高考的“全国卷”,它的权威性和覆盖面决定了它是最基础的“入场券”。由中国电子技术标准化研究院牵头的EIBench,最大的特点就是“标准化”与“综合化”。它不再让你挑环境,而是定义了统一的标准化流程,确保不同公司的模型在“同一条起跑线”上被比较。
它的任务库涵盖移动、推、拉、插入等8类核心原子动作,并引入了一套多维度的量化指标。这里面有一个指标尤其值得关注,安全性。是的,你没看错。当一个模型做出可能损坏设备或伤及自身的“危险操作”时,会被明确记录和扣分。这释放了一个强烈的信号,对于具身智能,安全不是锦上添花,而是基本功。

第二类“考卷”是司南为代表的评估标准。如果说EIBench是“全国卷”,那上海人工智能实验室推出的司南,就是一场“综合素质面试”。它提出的“五位一体”评估范式,覆盖了从底层算力、数据、模型到应用的全链路。但司南最精妙的设计,在于它的“三层级路径”。它不是一个单一的测试,而是由浅入深的“三关”。
第一关,静态数据集。考察模型最基础的理解能力,看它能不能“读懂题”。
第二关,高保真仿真。在虚拟世界里,让模型面对各种极端环境和复杂干扰,看它能不能“解对题”。
第三关,真实机器人。只有前两关都通过了,才进入最终的“实境考核”。
这种层层递进、优中选优的设计,从根本上杜绝了“偏科生”靠运气通关的可能性。一个模型在真实世界里表现优秀,意味着它在算法、数据、仿真、硬件协同上,都达到了真正的“全科优秀”。

第三份“考卷”是EWMBench与GM-100为代表的评估标准。如果说前两份考卷是“通识教育”,那么以智元机器人的EWMBench和上海交大的GM-100为代表的基准,就是针对特定能力的“拔尖人才选拔”。
比如EWMBench(具身世界模型评测基准),它不关心你能不能完成任务,它关心的是,你的“想象力”和“物理直觉”合不合理?它评估模型生成的场景是否连贯、预测的动作是否符合物理规律。一个能生成“合理”未来世界模型的AI,才真正具备了在物理世界中“举一反三”的潜力。这就像评价一个运动员,除了看比赛成绩,还要看他的身体素质、肌肉协调性等“底层天赋”。
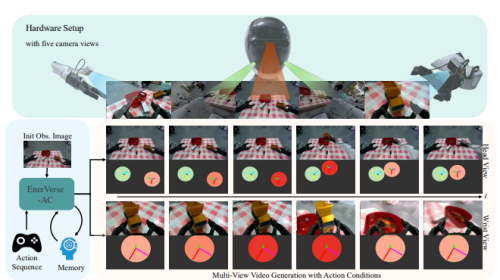
而GM-100的贡献在于,它提出了“部分成功率”这个概念。这简直是“非全即无”评价体系的一剂解药。它把100个长程任务精细拆解,记录每一步的完成情况。这让我们终于能看清,一个失败的模型,到底是在规划环节就错了,还是在执行环节手抖了?这种细粒度的评估,为模型优化指明了精准的方向。

PART 03
我们该如何重新“看”一家具身智能公司?
基于以上分析,当我们现在再去审视一家具身智能公司时,可以从新的维度来看。
第一,看“泛化”的广度,而不是“记忆”的深度。
优秀的公司,会主动公开模型在泛化能力上的表现。你可以在他们的技术报告中,寻找类似“泛化能力雷达图”这样的可视化呈现。一个强大的模型,应该能在物体颜色、位置、环境光照、背景干扰物等七大维度发生变化时,依然保持稳定的成功率。如果一家公司只展示在“完美环境”下的表现,而对环境变化避而不谈,那它很可能是在用“死记硬背”来掩盖“理解力”的缺失。
第二,看“执行”的轨迹,而不是“成功”的瞬间。
这意味着我们需要在看Demo视频时,把目光从“成功抓取”的那个爽快瞬间移开。去观察它的动作轨迹,它的运动是流畅自然的,还是充满生硬的抖动和试探?当它遭遇意外时(比如物体被碰倒),是立刻陷入死机状态,还是能重新规划路径?去关注它的长程能力,在完成一个20步的任务时,它的动作是否始终保持连贯,有没有出现“做一步想一步”的卡顿?这些细节,远比一个最终的成功/失败结果更能说明模型的智能水平。
第三,看“仿真”的逼真度,而不是“视频”的精美度。
仿真环境的重要性被大大低估了。一个负责任的团队,会告诉你他们如何利用高保真仿真来训练和测试模型的泛化能力。他们应该能清晰地阐述,仿真环境如何模拟了现实世界的复杂物理规律,以及如何在仿真中引入了大量随机性和干扰来“折磨”模型。一个在仿真中被打磨得足够“皮实”的模型,才更有可能在真实世界中“站稳脚跟”。

PART 04
写在最后,从“榜单竞技”到“生态共建”
我们正站在一个分水岭上。过去,评估标准的缺失导致了行业的“榜单竞技”,大家各说各话,自建赛马场。而现在,随着具身智能领域首个行业标准的发布与实施,以EIBench、司南、EWMBench为代表的评测体系,正在共同构建一个“基础共识”。它们就像一张张精密的地图,清晰地标明了通往通用具身智能的道路上,哪些是坦途,哪些是深坑。
对于公司而言,这不再是“要不要接受评测”的选择题,而是“如何在多维评测中证明自己”的必答题。模型能力不再是一个模糊的概念,而是一组清晰、可量化的素质指标。这无疑会加速优胜劣汰,让真正有技术底蕴的公司脱颖而出。
对于整个行业而言,一套科学、透明、多维的评估体系,是生态繁荣的基石。它能让科研人员精准定位技术瓶颈,让开发者明确优化方向,让投资者看清价值洼地,也让公众建立起对这项技术的理性认知。
当“成功率”的神话被打破,当每一个动作的合理性、每一次泛化的广度、每一段长程规划的逻辑都被纳入评价体系,我们才能真正看清,谁是在风口上翩翩起舞的“表演者”,而谁,又是在物理世界的荆棘中,一步一步踏实前行的“建造者”。
而这,正是我们这个时代,审视一项伟大技术时,所应有的专业与审慎。