财联社2月12日讯,据小米技术官微消息,小米2月12日宣布开源Xiaomi-Robotics-0。
据介绍,这是一个拥有47亿参数、兼具视觉语言理解与高性能实时执行能力的开源VLA模型。
小米机器人团队引入Action Proposal机制,强迫VLM模型在理解图像的同时预测多种动作分布。针对推理延迟引发的真机“动作断层”问题,小米机器人团队采用异步推理模式——让模型推理与机器人运行脱离同步约束、异步执行。
以下为原文(有删减):
小米开源首代机器人 VLA 大模型,刷新多项 SOTA!
在具身智能(Embodied AI)的浪潮中,我们始终在思考一个问题:如何让机器人既有“博学的大脑”,又有“敏捷的身手”?
现有的 VLA(Vision-Language-Action)模型虽然通过大规模参数获得了惊人的泛化能力,但在真实物理世界中,庞大的推理延迟往往让机器人表现得像个“反应迟钝的木头人”。
今天,我们对外发布:Xiaomi-Robotics-0。这是一个拥有 47 亿参数、兼具视觉语言理解与高性能实时执行能力的开源 VLA 模型。它不仅在三大主流的仿真测试中获得优异成绩,更在现实真机任务中实现了物理智能的泛化——动作连贯、反应灵敏,且能在消费级显卡上实现实时推理。
01
物理智能的钥匙:MoT 混合架构
物理智能的核心在于“感知-决策-执行”的闭环质量。为了兼顾通用理解与精细控制,Xiaomi-Robotics-0采用了主流的 Mixture-of-Transformers (MoT) 架构。
视觉语言大脑(VLM): 我们采用了多模态 VLM 大模型作为底座。它负责理解人类的模糊指令(如“请把毛巾叠好”),并从高清视觉输入中捕捉空间关系。
动作执行小脑(Action Expert):为了生成高频、平滑的动作,我们嵌入了多层的 Diffusion Transformer (DiT)。它不直接输出单一动作,而是生成一个“动作块”(Action Chunk),并通过流匹配(Flow-matching)技术确保动作的精准度。
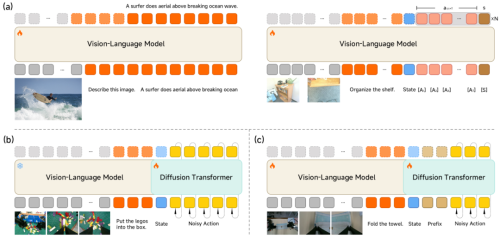
模型架构及训练方法:(a) VLM多模态与动作混合预训练;(b) DiT专项预训练;(c) 目标任务后训练
这种“大脑+小脑”的组合,让我们的模型既能听懂指令,又能像人类一样,在动作执行时保持极高的物理灵活性。
02
训练秘籍:两阶段的“进化论”
如何让模型既不丢失常识,又精通“体力活”?我们设计了一套严谨的训练配方。
▍跨模态预训练(Cross-Embodiment Pre-training)
大部分 VLA 模型在学动作时往往会“变笨”,失去本身的理解能力。我们通过多模态与动作数据的混合训练,让模型在学会操作的同时,依然保持强大的物体检测、视觉问答和逻辑推理能力。
VLM 协同训练:我们首先引入了 Action Proposal 机制,强迫 VLM 模型在理解图像的同时预测多种动作分布。这一步是为了让 VLM 的特征空间与动作空间对齐,不再仅仅是“纸上谈兵”。
DiT 专项训练:随后,我们冻结 VLM,专注于训练 DiT, 学习如何从噪声中恢复出精准的动作序列。这一阶段,我们去除了 VLM 的离散 Token,完全依赖 KV 特征进行条件生成。通过 DiT 专项训练,模型可以生成高度平滑、精准的的动作序列。
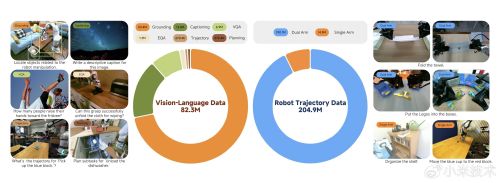
多模态数据与跨本体机器人数据的分布
▍后训练(Post-training)
这是解锁物理智能的核心路径。针对推理延迟引发的真机“动作断层”问题,我们采用异步推理模式——让模型推理与机器人运行脱离同步约束、异步执行,从机制上保障动作连贯流畅。为进一步强化模型对环境变化的响应敏捷性与运行稳定性,我们引入了:
Clean Action Prefix:将前一时刻预测的动作作为输入,确保动作轨迹在时间维度上是连续的、不抖动的,进一步增加流畅性。
Λ-shape Attention Mask:通过特殊的注意力掩码,强制模型更关注当前的视觉反馈,而不是沉溺于历史惯性。这让机器人在面对环境突发变化时,能够展现出极强的反应性物理智能。
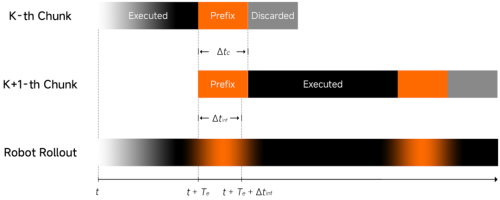
异步推理示意图,模型推理延迟不影响真机连续性运行
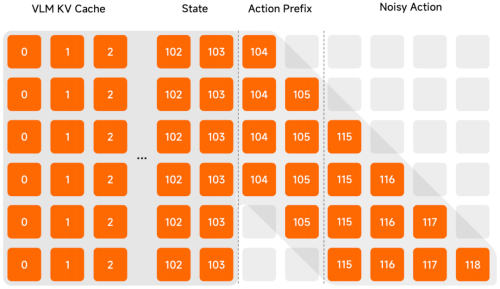
我们采用特殊的注意力掩码机制,有效缓解动作惯性
03
仿真与实战:全面 SOTA
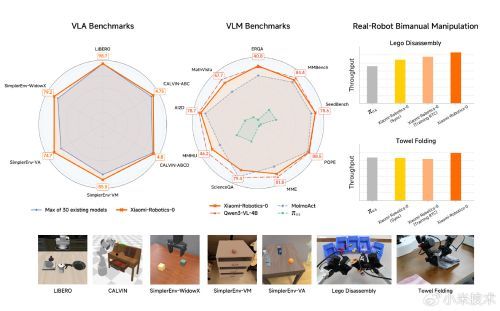
在多维度的测试中,Xiaomi-Robotics-0 展现出优异的表现:
仿真标杆: 在 LIBERO、CALVIN 和 SimplerEnv 测试中,模型在所有的 Benchmark、30种模型对比中,均取得了当前最优的结果。
真实挑战: 我们在双臂机器人平台上部署了模型并与行业标杆进行了横向对比。在积木拆解和叠毛巾这种长周期、高度挑战的任务中,机器人展现出了极高的手眼协调性。无论是刚性的积木还是柔性的织物,都能处理得游刃有余。
多模态能力:模型保留了 VLM 本身的多模态理解能力,尤其是在具身更相关的 benchmark 中表现优异,这是之前的 VLA 模型所不具备的。