该框架的行业价值在于,它将有效降低灵巧操作技能的学习成本与周期,使机器人能够快速掌握复杂的人类操作逻辑。通过高质量人类数据的规模化注入,RoboBrain-Dex解决了传统方法中技能泛化能力弱、迁移成本高的核心痛点,为工业制造、家庭服务、医疗辅助等高价值应用场景提供了可落地的技术底座。未来,RoboBrain-Dex会通过加入旁观者的视角来弥补第一视角的不足,同时不断提升对画面和动作的动态理解能力,从而让它在复杂多变的环境里操作得更稳定、更可靠,并推动具身智能灵巧操作从实验室演示迈向规模化商用,助力具身智能机器人在千行百业中广泛应用落地。
近日,智源研究院正式发布面向具身智能灵巧操作的新型预训练范式 RoboBrain-Dex,为具身智能机器人在真实场景中的落地提供了关键路径。该范式的核心突破在于:首次实现不依赖大规模机器人遥操作数据,即可完成高泛化能力的灵巧操作模型训练。
RoboBrain-Dex通过引入大规模人类第一视角操作视频数据作为主要训练来源,结合少量真实机器人操作数据进行分布对齐,显著缓解了机器人高质量操作数据稀缺的瓶颈。同时,模型通过运动学建模提取人类运动先验,将人类和机器人统一动作空间,实现人类动作和机器人动作的有效对齐。同时,该模型还将不同本体的动作和视觉信息都共享在统一token空间,支持统一的推理与决策流程,从而显著提升了跨机器人本体、跨场景和长时程任务的泛化能力。
RoboBrain-Dex直面当前具身智能发展的两大核心痛点:数据稀缺与泛化不足。当前,对于拥有十几个甚至更多自由度的灵巧手系统而言,高维动作空间导致遥操作数据采集成本极高,且不同“灵巧手”结构之间差异显著,造成数据难以复用、模型难以迁移。真机数据有限使得模型难以学习到足够丰富的操作经验,严重制约了机器人在不同应用场景的泛化落地能力。机器人只能在见过的、相似的环境中稳定运行,一旦面对新场景、新物体或新任务,就容易出现判断失误、动作失效等问题,无法快速适应环境变化与任务差异,难以从有限经验中提炼出通用、可迁移的控制策略,最终导致在真实场景中可靠性不足、复用性差,难以规模化部署。RoboBrain-Dex正是为解决这一挑战而设计——它不再依托于少量的机器人数据采集,而是“借力”海量易得的人类操作视频,实现了从“小数据、弱泛化”向“大数据、强泛化”的范式跃迁。
RoboBrain-Dex系统性地将大规模人类视觉-动作数据与机器人视觉-动作对齐,并实现统一建模与跨本体迁移的灵巧操作预训练。相较于传统的基于纯仿真或小规模遥操作数据的训练方法,RoboBrain-Dex在数据效率、泛化能力和部署灵活性方面具有显著优势。尤其在不依赖特定硬件数据的前提下,即可实现对新机器人平台的快速适配,为未来具身智能机器人具备“看人做、自己学、上手用”的类人学习能力奠定了技术基础。

实验结果显示,RoboBrain-Dex在多项真实世界灵巧操作任务中取得显著提升,在支持跨具身形态(cross-embodiment)的长时程双臂协作(bimanual dexterous manipulation)、复杂物体操作等挑战任务上成功率提升40-60%,并在未见物体与新环境下展现出更好的跨场景泛化能力。
RoboBrain-Dex验证了一条更可扩展的训练路径,在显著降低数据采集成本的同时,仍能在复杂操作任务中保持优异效果,为后续在更多任务、场景与平台上的扩展奠定坚实基础。
1、技术创新:利用人类第一视角操作
数据的跨本体统一预训练策略
高效便携的第一视角人类动作数据采集系统
 【图说】便携式glove-tracker系统:通过Manus Quantum手套精确捕获25个手部3D关键点,结合VIVE Tracker记录6自由度腕部与头部位姿,配合头戴式相机同步采集第一视角视觉信息。
【图说】便携式glove-tracker系统:通过Manus Quantum手套精确捕获25个手部3D关键点,结合VIVE Tracker记录6自由度腕部与头部位姿,配合头戴式相机同步采集第一视角视觉信息。
传统动作捕捉依赖多相机阵列与专业场地,存在部署成本高、易受遮挡、数据采集效率低等局限。RoboBrain-Dex创新推出便携式 glove-tracker 系统,在采集高精度手部数据同时,摆脱对固定场地与昂贵设备的依赖,可在家庭、工厂、户外等真实场景灵活部署,实现随时随地、无感化的高质量人手动作采集,大幅降低数据获取门槛,支持大规模、长时间、多样化数据收集。该方案不仅提升了数据采集的易用性与真实性,更有望构建分布式数据采集网络,通过汇聚海量真实场景下的手部动作数据,为训练更通用、更具环境适应性的智能体提供关键支撑。
基于这套系统和开源数据的处理,智源研究院自采人类第一视角操作数据,并融合互联网开源的人类与灵巧手第一视角数据,构建了EgoAtlas数据集。为解决不同数据源的动作表示不一致问题,统一采用相机坐标系作为标准,确保了跨数据集的一致性表示。

多源数据预训练与高效微调
RoboBrain-Dex采用统一的Vision-Language-Action(VLA)框架,将视觉观测、语言指令与动作输出在同一模型中联合建模。预训练阶段,模型融合人类第一视角示范与机器人第一视角交互等多源数据,学习更广泛的操作经验与可迁移表征。下游任务中,模型无需依赖大规模在线交互或从头训练,通常仅需少量真实机器人数据微调,即可将预训练能力快速泛化到具体的真实操作任务,显著提升数据效率并降低部署成本。
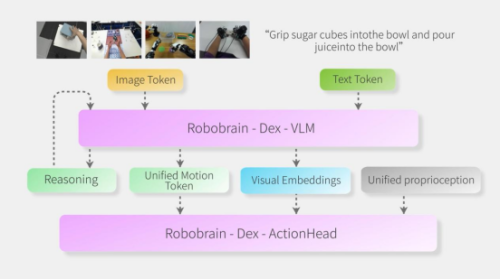
面向长时程与多步骤任务,RoboBrain-Dex引入标记驱动的“推理—执行”解耦机制:模型可在生成过程中通过特定标记(如[BOR])进入任务分解/中间推理阶段,通过(如[BOD])切换到动作生成阶段,并将相应隐表示传递给动作解码器以输出连续控制指令,从而更稳定地实现“先推理、后执行”的决策流程。
创新的Visual-Motion动态建模框架
多源第一视角数据的独特挑战在于本体视觉差异以及视角移动,为此,RoboBrain-Dex提出了Visual Dynamics和Motion Dynamics的双重建模策略。
Visual Dynamics专注于建模第一视角视觉观测的时序演化,通过引入手部运动作为条件,在隐空间构建与操作相关的视觉状态的动态表示,使模型理解"哪些视觉特征变化和动作相关"。Motion Dynamics则建模动作本身的时序结构,通过RQ-VAE将连续运动轨迹压缩为紧凑的离散token,在保留关键运动信息的同时大幅降低表示维度。这种离散化不仅提高了计算效率,更使模型能够从大规模数据中充分学习运动先验,实现人类和机器人动作在统一潜空间中的对齐表示。

2、实验验证:在复杂真实环境中实现
高成功率与强鲁棒性的灵巧操作
RoboBrain-Dex在多项真实世界灵巧操作任务中展现出卓越性能。在仅使用少量机器人数据微调的情况下,模型在复杂操作任务上的成功率显著超越基线方法。更重要的是,执行过程展现出良好的稳定性和动作连贯性——即使在视角变化、物体遮挡等挑战性条件下,模型仍能保持鲁棒的操作能力。

跨任务泛化实验显示,面对训练中未见过的新物体组合、不同初始状态和变化的操作环境,RoboBrain-Dex依然保持较高成功率。这种泛化能力源于多源数据预训练带来的丰富操作分布,使模型学习到更加抽象和通用的操作先验。

在指令跟随任务中,模型准确理解并执行各种自然语言指令,即使面对语义更抽象或表达方式变化的指令,仍能生成与意图一致的动作序列。

消融实验进一步验证了各模块的贡献。移除Motion Dynamics建模或采用连续动作表示都会导致性能明显下降,证实了通过RQ-VAE构建的紧凑动作token在保留关键运动信息和提升训练效率方面的关键作用。Visual Dynamics的引入则显著提升了模型在复杂视觉条件下的鲁棒性。
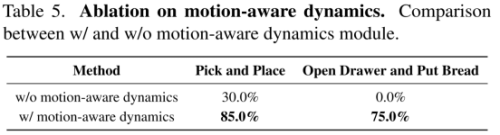
RoboBrain-Dex在基础操作、复杂任务等维度均实现了对GR00T N1.5、π0.5等主流模型的超越,其核心创新(运动感知动力学模块)是提升复杂时序任务成功率的关键,同时在语言指令跟随与环境鲁棒性上也展现出领先优势。
在泛化能力评估中,RoboBrain-Dex同样表现优异:在“跨背景泛化”任务里,RoboBrain-Dex成功率达70.0%,显著高于π0.5(50.0%)和GR00T N1.5(65.0%);在“杂乱场景”中,RoboBrain-Dex以70.0%的成功率超越两款基线模型(55.0%和60.0%);在“物体类别泛化”任务中,RoboBrain-Dex同样以70.0%的成绩优于π0.5和GR00T N1.5(均为65.0%)。这表明,RoboBrain-Dex在环境结构变化、物体属性泛化及复杂场景干扰等方面具备更强的适应能力。
RoboBrain-Dex为具身智能机器人灵巧操作领域带来关键范式转变:从依赖昂贵、低效的机器人本体数据采集,转向充分利用丰富、可扩展的人类操作数据。这一转变不仅彻底打破了长期制约行业发展的数据稀缺瓶颈,更提供了一条通往通用具身智能的高效技术路径。