具身智能,正在经历一场静悄悄的"祛魅"。
过去两年,VLA(视觉-语言-动作)与 WMA(世界模型-动作)模型研究论文快速增长,各类技术演示令人目不暇接,行业热度空前高涨。然而,在光鲜的 demo 背后,一个系统性的尴尬正在蔓延:大量在仿真环境中表现出色的模型,一旦被部署至真实物理场景,便迅速失效。桌面高度差了5毫米,操作物体从刚性换成了软布,背景光线发生了变化——这些在人类眼中微不足道的扰动,足以让一个精心训练的具身模型当场翻车。
这不是偶发现象,而是具身智能领域的系统性顽疾:模型学会了记忆,却还没学会真正的理解。

带着这一核心追问,由原力灵机与 Hugging Face 联合发起的全球首个大规模真机评测平台RoboChallenge,正式发布Table30 V2。这是对上一代评测体系的深度重构,也是行业第一次将模型泛化能力纳入系统性量化考核的严肃尝试。它以“面向下一代模型的大规模真机原生泛化评测”为核心标准,从任务升级、评测升级到系统升级三个维度深度重构:通过引入更严苛的软体、工具使用及双臂协作任务,支持零样本与域外泛化测试,并实现3倍于往届的系统吞吐量,为全球具身智能研究者打造一把精准的"泛化标尺"与公平、开放的真机竞技场。同时Table30 V2预览版将作为 RoboChallenge CVPR 2026 Workshop 竞赛的首秀上线发布。
01.
为什么旧的评测体系不够用了?
在深入 Table30 V2 之前,有必要先厘清一个问题:现有的具身智能评测,究竟差在哪里?
答案指向一个本质缺陷:它们太容易被攻克了。在传统评测框架中,研究团队普遍针对特定任务进行单独精调(Fine-tuning),催生了大批考试型模型——在固定场景下表现优异,换个角度或物体便立刻失灵。与此同时,真机测试长期面临成本高昂、难以复现、缺乏统一标准等核心痛点,导致模型评估往往停留在仿真器或高度受控的实验室环境中,其现实世界智能成色几何,始终难以量化评判。
这意味着,当一个模型在排行榜上占据高位时,我们实际上并不知道它在真实家庭或工厂场景中是否同样可靠。这种认知盲区,正是制约具身智能从实验室走向大规模应用的隐性障碍。
Table30 V2 的逻辑起点,正是打破这道障碍。
02.
任务升级:让真实世界的复杂性无处遁形
 Table30 V2任务集
Table30 V2任务集
泛化能力的缺失,往往根植于对简单任务的过拟合。Table30 V2 的第一维升级,直指任务集本身。
在保留 12 个经典任务的基础上,平台新增 18 个全新双臂灵巧操作任务,将总任务数扩展至 30 个高难度场景。这些新任务并非随意堆砌,而是围绕三个方向精心设计,每一个方向都对应着当前 VLA 模型的现实短板。
从硬到软的跨越,是本次任务升级颇具代表性的突破。Table30 V2 引入了对绳索、布料等软连续体物体的操作任务。与刚性物体不同,这类物体形变无限、状态不固定,任何预设的几何假设都将失效。模型必须在实时感知中动态建模物体状态,并持续自适应地调整控制策略——这直接将挑战拉升至空间推理与自适应控制能力的极限。
工具与空间的深度交互,则考验的是模型对物理世界的因果推理。新增任务要求机器人准确使用工具,并实时理解工具与目标物体之间复杂的物理依赖关系。这不仅是精度控制的工程问题,更是对模型是否真正掌握物理常识的深度摸底——它能否理解施力方向、接触面积与操作结果之间的因果链条,而非仅仅复现一套固定的动作序列?
双臂协作的刚性约束,则将时序建模与多模态协调推向新高度。大量新任务要求双手在动态受限的环境下实现高精度同步控制,左右手之间的实时配合对模型的全局规划与局部精细控制同时提出了严格要求。
另外,在硬件层面,Table30 V2 还引入了新一代移动双臂操纵平台 DOS-W1(配备三角尖端夹具),与经典 Aloha 系统并存,构建双机型并行评测机制。这一安排在降低参与门槛的同时,通过跨硬件配置的对比测试,严格验证了模型在不同物理实体上的跨平台鲁棒性。
03.
评测升级:终结为比赛而调参的旧游戏

任务变难了,但如果评测协议本身存在漏洞,聪明的研究者总能找到钻空子的方式。Table30 V2 的第二维升级,从根本上封堵了这些漏洞。
多任务范式的强制推行是第一道闸门。平台明确禁止为每个任务单独训练专用模型的作弊式优化,强制要求参评者提交具备通用理解能力的单一模型。这一规则与构建通用具身大模型的行业大趋势高度一致,也让评测结果真正反映模型的泛化能力,而非针对性调参的技巧。
零样本(Zero-shot)测试,是本次升级最具颠覆意义的改变。Table30 V2 在物体级和环境级两个层面系统性地引入零样本测试:模型必须面对训练集中从未出现过的物体外观,从未见过的场景背景,乃至动态变化的干扰条件——例如桌面高度被随机微调。这一设计的深层逻辑在于:真正的智能,是推断阶段实时生成的,而非在训练阶段提前记忆的。无法通过零样本测试的模型,不论在单任务指标上多么亮眼,都不能被称为真正具备泛化能力。
分层泛化矩阵(In-Domain vs. Out-of-Domain),则将压力测试推向极致。除传统域内(In-Domain)评估外,Table30 V2 新增包含域外(OOD)场景的高阶测试——极端情况下,测试台甚至会被替换为沙发等完全不可控的家居表面。这不再是一场分数游戏,而是一次对模型"智能本质"的直接追问:它理解的是任务本身,还是特定视觉配置下的条件反射?
04.
系统升级:速度也是科研竞争力
在算法研究中,迭代速度即生产力。等待真机测试结果所消耗的时间,是制约研究节奏的一道隐性瓶颈。Table30 V2 的第三维升级,将这道瓶颈彻底打通。
通过大规模增购主流机器人硬件并优化调度算法,Table30 V2 实现了3倍于往届的系统吞吐量。与此同时,任务准备方式从"像素级严苛对齐"调整为更贴近现实的"粗略对齐",大幅压缩了任务间的空转时间,确保研究团队能够高频次地获取测试反馈,将"训练-测试-迭代"的研发飞轮真正转起来。
排行榜中新增的完成时间(Time to Complete)评分维度,则赋予了这一升级更深的战略意义。它倒逼研究者在追求成功率的同时,优化策略的实际执行效率——一个需要30秒推理才能完成一次抓取的模型,在真实部署场景中毫无价值可言。这一指标的加入,让评测结果与真实落地需求之间的对齐度大幅提升。
05.
数据说话:50%的天花板与接近零的地板
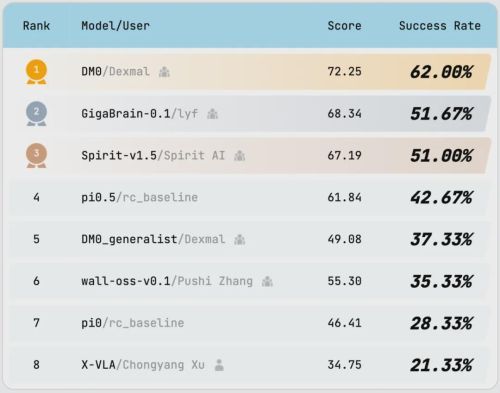 RoboChallenge 最新榜单(截止至2026.03.24)
RoboChallenge 最新榜单(截止至2026.03.24)
Table30 V2 并非凭空而来,它的设计背后有一份来自真实世界的清醒报告作为支撑。
基于 2025 Q4 至 2026 Q1 期间平台完成的数万次严苛远程真机测试,RoboChallenge 年度报告呈现了当前具身智能模型的真实能力边界。当前表现最佳的模型DM0,整体成功率62%;GigaBrain-0.1,成功率约 52%;Pi0.5 为 42.67%;第10名 RDT-1B 仅为 15%。“叠碗”和“物体移入盒子”成为多数模型首选的验证任务,堪称具身智能领域的“Hello World”;而涉及多步骤序列推理与精细操作的任务,如“制作三明治”成功率至今接近于零。
尤其值得关注的是,尽管参测模型在语义指令理解上已表现出一定能力,但在精细操作任务中的成功率普遍低于 15%。这揭示了当前 VLA 模型普遍存在的“理解-执行”断层:听得懂,做不到。这些平台上沉淀的大量真机失败数据,构成了一份公开的错题集,是推动模型迭代的宝贵参考资产,也是 Table30 V2 设计思路的现实依据。
06.
开放社区,凝聚行业共识

RoboChallenge 不是一家公司的产品,而是行业共识的结晶。自 2025 年 11 月组委会成立以来,原力灵机、Hugging Face 联合集结了智源研究院、智元机器人、Qwen、星海图、自变量、清华大学、西安交通大学及 GOSIM,共同推动具身智能真机评测走向规范化与标准化。DM0、GigaBrain-0.1、Spirit-v1.5、Pi0、Pi0.5、RDT-1B、CogACT、OpenVLA-OFT 等主流开源模型已完成测试上榜,极佳视界、智源研究院、中移杭研、星海图、地平线等机构的模型正在紧锣密鼓地推进真机实测。平台活跃用户已覆盖中国(58.3%)、美国(22%)、新加坡(10.1%)等多个国家和地区,国际化社区生态正在迅速成形。
07.
CVPR 2026:泛化时代的第一场真机竞技
Table30 V2 的预览版,将作为RoboChallenge CVPR 2026 Workshop 竞赛的首秀正式亮相。这是具身智能领域首次将大规模真机评测竞赛带上顶级计算机视觉学术会议的舞台,最多 10 支队伍将在真实机器人集群上与全球顶尖算法同台较量,以真实数据说话。

关键时间节点:报名截止 4 月 25 日;评测基准四月中旬上线;最终竞赛 5 月 15 日。竞赛结束后,平台将持续向全球研究者开放评测基础设施,让每一个有想法的团队都能在真实机器人上验证自己的模型。
泛化,是具身智能通往物理世界通用性的必由之路,也是下一座需要全球研究者共同攀登的山峰。Table30 V2,已经开路。
报名及详情:
https://robochallenge.cn/competition