过去一年,机器人端到端操控学习彻底火了。从波士顿动力去年底的全身操控演示,到 CES 上 Atlas 刷屏全网,背后的核心技术,都是丰田研究院(TRI)的大行为模型 LBM。

这套基于多任务扩散 Transformer 的轨迹生成方案,没有堆砌 VLM 大模型,仅靠轻量化视觉、文本编码器就跑出了炸裂效果。但官方一直没开源代码,行业内既没法公平对比性能,更没法直接复现落地。
近日,机器人领域研究者 Bryson K. Jones 在个人博客发布长文,基于公开资料、TRI 的原始论文,结合补充研究与工程直觉,完整还原了一套可执行的实现方案,拆解了技术实现全流程,并将代码正式开源到社区。
PART 01
轻量化LBM凭什么惊艳?
很多人第一眼会把这套方案当成 VLA 模型,但二者本质完全不同。
Bryson没有采用预训练大尺寸视觉 - 语言主干,而是选用了参数规模小得多的轻量化视觉与文本编码器,在算力消耗上做了大幅克制。
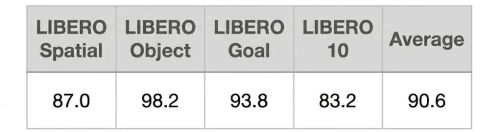
当前机器人操控领域的基准评测体系仍处于早期阶段:除了 LIBERO 这类简单任务,复杂场景下的评估大多偏主观、不够严谨,不在自有平台上亲自复现,根本无法判定谁是绝对的 SOTA。但从公开演示和本次复现的结果来看,这套策略的表现已经足够惊艳。
它最大的亮点,就是无需堆砌海量算力,就能实现顶尖性能。针对单任务到少任务数据集,仅需 100-200 条演示样本,在单张 H200 显卡上训练约10小时,成本仅几十美元,就能快速迭代出可用的策略。
Bryson 将代码拆分为两个版本开源:一个是独立仓库,包含极简训练流程与推理示例,方便研究者修改结构、做消融实验;另一个则直接集成进 Hugging Face LeRobot 生态,开箱即用,面向希望快速在实体机器人上部署的开发者。
PART 02
TRI LBM 架构全复现:DiT改造适配轨迹生成
TRI原论文中的架构图设计偏简洁,不少实现细节只能靠研究者自行推断。而这次复现则把每一层的逻辑、参数与实现都做了明确落地,彻底消除了模糊空间。
方案的核心,是将 Meta 原本用于 2D 图像生成的扩散 Transformer(DiT),改造为适配 1D 序列建模的轨迹生成器,让整条动作轨迹的生成过程,都以机器人的观测信息为条件。
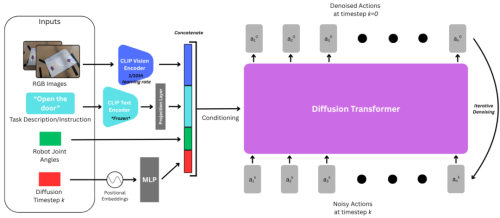
训练采用经典的行为克隆方式,数据通过遥操作采集。TRI 在原论文中已经完成了单任务与大规模预训练的性能分析,本次复现也在 LIBERO 基准上完成了验证,结果稳定可靠。
整套架构的模块化设计非常清晰,没有冗余的复杂设计,后续无论是替换组件还是做功能扩展,都十分便捷。
PART 03
CLIP 完胜 ResNet 与 DINOv3:机器人视觉编码器选型
复现采用的是CLIP ViT‑B/16编码器,全程只提取CLS token编码,不使用任何 patch 嵌入。这样做能让特征保持紧凑,同时完整保留预训练主干的强语义对齐能力。
当前机器人扩散策略主流仍在使用 ResNet 视觉编码器,而在对比测试中,CLIP 带来了非常明显的性能提升。
编码器采用端到端联合训练,学习率固定为模型其他参数的 1/10。视觉模块可以充分适配当前环境与任务,同时守住大规模预训练带来的强泛化性能。
实现中还额外加入了DINOv3编码器,使用方式与 CLIP 完全一致,只抽取 CLS token。实测效果并未超越 CLIP,甚至出现性能下滑。根本原因在于,DINOv3 与 CLIP 的训练目标差异明显,缺少语义对齐环节,空间特征再强,也无法直接转化为机器人操控的实际增益。 Bryson 保留了这一模块,留给后续研究者继续探索优化空间。
PART 04
文本编码器:冻住CLIP,只加一层投影
模型的语言条件输入直接使用 CLIP 的文本分词器与嵌入层,这部分参数在训练全程保持冻结。整个文本分支里,只有一个投影层参与学习,负责将 CLIP 文本嵌入映射后,接入模型的总条件向量。
这套设计带来极低的算力开销,训练过程也更稳定。但 trade‑off 很明显:语言引导能力偏弱。模型只用到浅层文本嵌入,没有形成深度对齐的多模态联合表征。
放到多任务学习场景里,这依然是性价比极高的选择,不用为了语言理解承担大模型的算力负担。
PART 05
本体感知信息:直接拼接,不做额外编码
关节角度这类本体感知数据,不经过预处理,也不做额外编码,直接拼入条件向量。
实际使用中效果完全可用,只是本体特征维度,比外部感知特征与语言嵌入低了一个数量级以上。
理论上可以替换成更复杂的编码方式,但提升空间很小,基本属于边际优化。
PART 06
DiT 改造关键:图像生成模型改造成轨迹生成器
核心预测模型采用改版 DiT,直接将动作序列建模为具有时间关联的连续轨迹。
每一步去噪过程中,模型负责预测噪声,并以此迭代修正动作输出。噪声预测基于拼接后的完整条件向量,包括编码后的图像、任务描述嵌入、本体姿态角度以及扩散时间步信息。
动作数据格式为 (N, H),N 代表动作空间维度,H 是轨迹时域窗口长度。初始状态从高斯分布采样,经过多轮去噪后生成最终可执行轨迹。
Transformer 模块同时支持标准位置编码与旋转位置编码 RoPE。实测表明,RoPE 在长时域范围内对相对位置的建模更稳定,性能与鲁棒性优势明显,因此作为默认配置启用。
PART 07
两种生成目标:扩散与流匹配
复现版本直接支持两种训练目标,切换很方便。
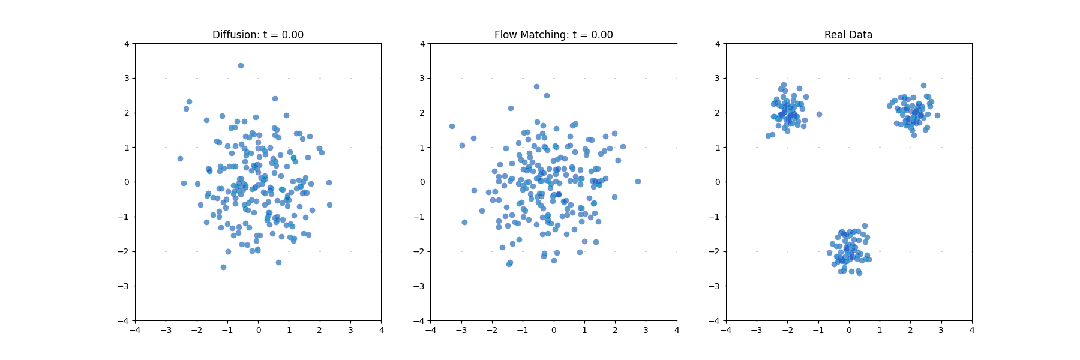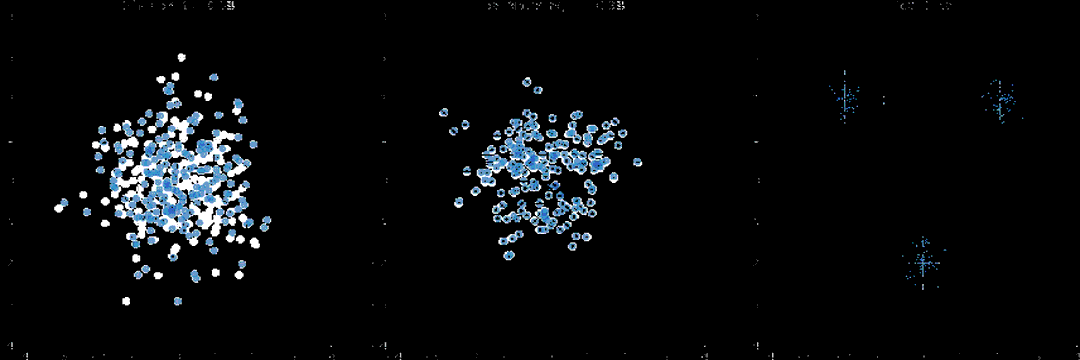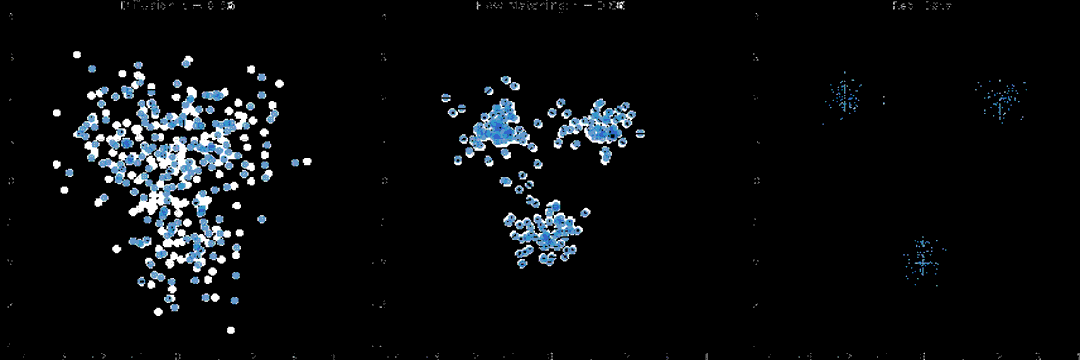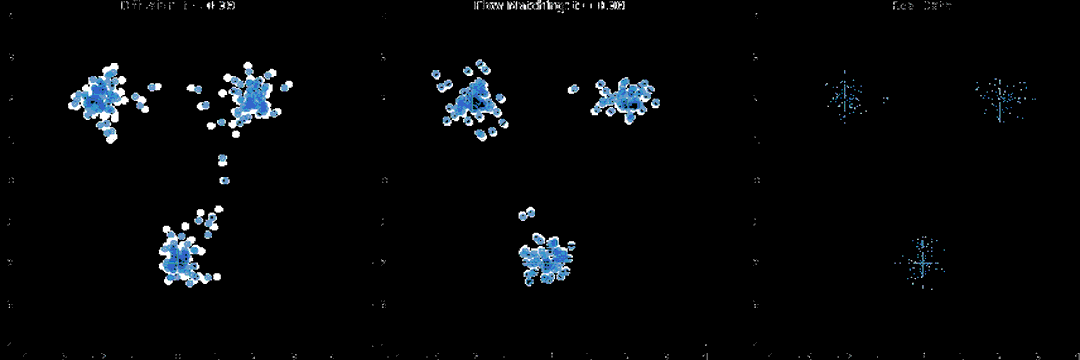
经典扩散目标:标准DDPM/DDIM流程,往动作序列逐步加高斯噪声,模型学习预测并移除噪声,最小化预测噪声与真实噪声的L2损失,学到动作轨迹上的分数函数。
流匹配目标:用常微分方程建模轨迹演化,模型学瞬时速度场,把含噪声样本推向数据分布。训练更平滑,收敛往往更快。还加入了Physical Intelligence在π0模型里用到的beta分布时间步采样,实测能加速训练,推理生成的轨迹质量也更高。
PART 08
现有短板:轻量化LBM的语言可控性问题
这套架构存在一个无法回避的短板:语言可控性偏弱。
模型只用到 CLIP 文本编码器的浅层嵌入,提供的条件引导信号本身就不够强。
最典型的问题体现在组合指令上:让机器人把已学会的多个技能串联执行,模型经常无响应或输出不稳定,很容易卡在训练中见过的某个单一技能上,不会根据精细的指令描述去合成、排序连续动作。
在场景固定、任务单一的落地场景中,这个缺陷并不致命。轻量化 LBM 在限定的操控任务里已经能发挥实用价值,偏弱的语言条件反而让模型评估更简单。但如果要做开放世界泛化、追求强指令遵循能力,这套方案会很快触及性能上限。
PART 09
训练排障指南:解决常见异常问题
这类模型目前仍处于早期阶段,训练过程中很容易出现各种难以解释的异常问题,Bryson根据实际调试经验,整理出了一套可直接使用的排障指南。
最常见的问题是推理时机器人完全不动或输出坍缩,表现为动作输出几乎为零,全程卡住,可能在轨迹一开始就失效,也可能执行到一半突然停止。这种情况通常由两个原因导致,一是单任务演示样本太少,20 到 50 条很容易出现坍缩,增加到 300 条左右才会明显好转,二是数据集中存在视觉特征、几何形态高度相似的任务,浅层的 CLIP 文本条件无法有效区分。对应的解决办法也很直接,把单任务样本量提升到 300 条以上,训练步数拉到 5 万至 10 万步,不要看到损失曲线平稳就提前停止,同时把指令写得更明确直白,避免过长描述。
另一个高频问题是执行错误任务,机器人动作流畅,但完成的并不是指令指定的任务。这一般是因为文本提示过于相近、歧义较大,部分任务样本太少被高频任务覆盖,或是不同任务在视觉特征、动力学特性上重叠度过高。想要改善可以从三方面入手,把任务描述写得更有区分度,训练采样时对表现较差的任务提高权重,也可以针对出错的任务单独微调几千步,通常能快速提升指令执行准确率。
PART 10
双版本开源:支持不同场景需求
本次复现提供了两套完整部署方案,面向不同使用人群。
独立极简仓库只保留核心实现,适合希望深入研究源码、修改网络结构、开展算法实验的研究者,不与任何硬件直接绑定,使用者可自行对接执行机构。仓库内部还预留了实验性视觉编码器等扩展模块,方便后续进行自定义修改与测试。
LeRobot集成版更适合硬件落地场景,开箱即可运行,实现逻辑尽可能贴近原始策略,结构清晰易懂,可直接作为开发基线使用。
两种实现均默认采用 LeRobotDataset 格式,持有该格式数据集的用户可以直接启动训练。目前方案仅在单臂与双臂简单操控场景完成验证,但参考波士顿动力的公开演示效果,在人形机器人全身操控任务中同样具备出色的运行潜力。
PART 11
未来研究方向
Bryson 表示接下来的研究重心,将放在RL 微调、表征学习、新型传感模态编码器这几个方向上,也是当前机器人学习领域最受关注的核心赛道。
从波士顿动力令人震撼的现场演示,到如今低成本、可复现的平民化版本,机器人操控大模型正在真正走出实验室,迈向小样本、低成本、快速迭代的实用化阶段。不需要超算集群,不需要百万级数据,普通实验室和个人开发者就能训练出可用的多任务操控策略。
这是机器人端到端学习,距离实际落地最近的一次。
参考资料:
https://brysonkjones.substack.com/p/dissecting-and-open-sourcing-multitask-diffusion-transformer-policy
独立仓库开源: https://github.com/brysonjones/multitaskditpolicy
Hugging Face LeRobot: https://github.com/huggingface/lerobot