纯文本指令,正在卡住具身智能的 “最后一公里” 。
在堆满同款瓶子的桌面、无特征的空白台面、从未见过的陌生物体面前,再强大的VLM也会陷入定位困境,文字再详细,也描述不清人类 那种“那个、这里、那里” 的模糊意图。

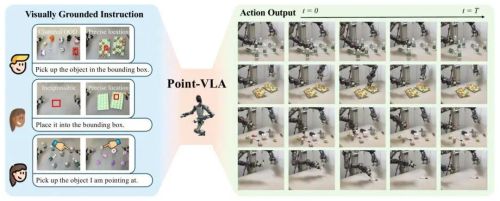
近日,千寻智能高阳团队 给出了一个简单到极致的解法: 给机器人指令加一个视觉框 。
团队提出全新的 Point-VLA 策略,不用更改模型骨架、不用海量人工标注,只要在画面上画个Bounding Box,配上拿起放在这里极简指令,机器人就能瞬间锁定目标,在人类都觉得复杂的场景里完成精准操作。
该研究成果 直接把具身操作的 平均成功率拉到92.5% ,在纯文本完全失效的场景里,实现了从25%到95%的跨越 。
PART 01
文本指令的天生缺陷,被彻底戳穿
过去几年,RT-2、π₀、π₀.₅、OpenVLA等VLA模型一路狂飙,把文本到动作的对齐做到了新高度。但 高阳 团队在真实机器人实验里发现一个致命问题:
文字,根本无法描述所有空间意图。
论文里明确指出两个无法绕过的瓶颈:
不可表达的指代 。不规则黏土、空白桌面的精确点位、八瓶一模一样的饮料,文字再复杂也会歧义。就算VLM定位准确率60%-70%,纯文本VLA的实际操作成功率只有25%。
泛化能力受限。遇到没见过的物体、复杂空间布局,文本模型直接失灵,语言和动作之间存在一道无法填补的对齐鸿沟。
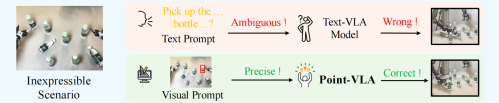
Point‑VLA 通过显式视觉锚定解决了语言无法表达的指代问题。在存在大量视觉相似物体的场景中,即便使用复杂且详尽的文本描述,也无法实现可靠泛化,进而导致动作模糊与执行错误。
在杂乱抓取、蛋槽精准拾取、无参考平面放置这些任务里,纯文本VLA基本宣告失效。
团队做了比较直观的对比:同样是拿起左数第二个瓶子右边那瓶,纯文本VLA频繁抓错;而Point-VLA只需要画个框,配上拿起二字,一次成功。
PART 02
只加一个框,VLA瞬间指哪打哪
Point-VLA的核心设计,简单到让人意外。它没有推翻现有VLA架构,而是做了一个 即插即用的增强接口 :
在标准文本+多视角图像输入之外,额外增加 第一帧锚定图像,在起始画面上,给目标物体画一个 视觉框 。
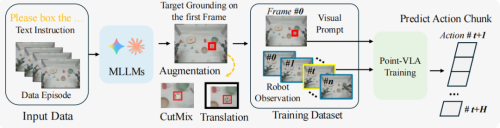
文本只负责表达动作意图(pick up/place),所有精准空间信息,全部交给这个视觉框。
形式上就是: 视觉锚定指令 = 极简文本 + 带框的第一帧图像
模型在每一步推理时,同时看当前场景和这个带框目标,全程保持像素级的目标锁定。
团队试过坐标文本、掩码遮挡等多种方式,最终证明: 直接在原图上画框,效果最好 。它保留全局上下文,又给出明确局部指向,不会因为 场景偏移 而 失效。
PART 03
不用人工标框!MLLM自动完成全流程标注
一个现实问题:给每段机器人演示视频画框,成本太高。
为此,研究团队借助多模态大模型,搭建了一套四步全自动标注流程,几乎不需要人工参与 。
先让多模态大模型结合完整视频与文本指令,判断任务属于抓取还是放置、并确定执行动作的机械臂。定位夹爪闭合或张开的关键帧。再在顶视图画面中自动生成紧贴目标的视觉框。最后输出结构化 JSON 数据,直接用于模型训练。
在固定顶视相机的配置下,这套自动标注方案的准确率可达 92%,完全满足真实机器人场景的训练需求。
为避免模型死记硬背绝对坐标、过度拟合特定物体外观,团队还加入了两项轻量化数据增强策略:一是随机平移,让 视觉框 与画面同步移动,使模型学习相对位置而非固定像素坐标。二是局部 CutMix,将 视觉框 内的区域替换为 ImageNet 图像块,降低模型对目标外观的依赖。
经过这套优化,Point‑VLA 即便面对蛋槽偏移 10 厘米、或是完全未见过的陌生物体,依然能保持稳定可靠的操作表现。
PART 04
双模态一起训:纯文本性能反而更强
Point‑VLA 并未舍弃纯文本指令,而是采用1:1 比例混合训练的方式,将纯文本指令数据与文本加视觉 框 的数据一同输入模型。
实验结果出人意料:即便关闭视觉框功能、仅以纯文本进行推理,Point‑VLA 的表现也优于仅使用纯文本训练的基线模型。在相对位置定位、矩阵布局拾取、基于参照物定位这三类典型空间指代任务中,Point‑VLA 的纯文本模式均实现全面领先。
这意味着,视觉锚定训练不是投机取巧,而是真的让模型学到了更深的空间语义和语言-动作对齐能力 。
PART 05
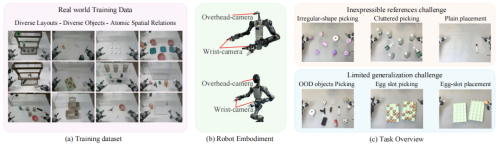
机器人实战 :6项任务平均92.5%成功率
研究团队在真实场景中分别部署了双臂机器人和全身人形机器人,集中测试了 6 项对精准定位要求极高的操作:不规则物体抓取、未知物体(OOD)抓取、杂乱场景抓取、蛋槽精准取放,以及无特征桌面放置。这些任务都是纯文本指令很难说清、传统模型容易出错的高难度场景。
实验选取了两组当前主流的强基线模型做对比:一组是纯文本驱动的 VLA 模型,另一组是结合文本与非锚定图像块的Interleave-VLA。从整体成功率可以直观看出差距:Point-VLA 达到92.5%,纯文本 VLA 仅40.0%,Interleave-VLA 为32.4%,提升非常明显。

在典型难点任务上,Point-VLA 的优势更加突出。比如蛋槽拾取这类文字极易混淆、靠描述分不清目标的任务,成功率从 10% 直接飙升到 95%;而在无特征桌面放置这种文字完全无法精准描述位置的任务上,纯文本模型只有 20%,Point-VLA 直接冲到 90%。
更实用的是,Point-VLA 采用即插即用设计,使用门槛很低。它可以直接兼容 π₀.₅、π₀等主流 VLA 骨架,不用重新设计网络架构,只要轻量化微调就能在双臂机器人、全身人形机器人上直接迁移部署,快速落地。
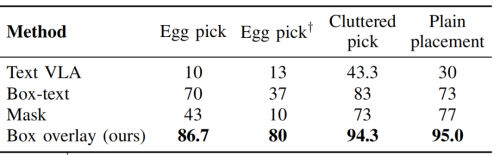
研究团队进一步在杂乱抓取 + 容器放置这组跨场景任务上验证通用性:在 π₀.₅双臂平台,文本基线 43.3% 提升至 94.3%;π₀.₅人形平台,从 41.7% 提升至 83.3%;π₀双臂平台,从 20% 提升至 63.3%。
整体结果表明 : 无论模型大小、 无论是双臂还是人形机器人,Point-VLA 都能带来稳定且大幅的性能提升,真正解决了纯文本指令说不清楚、指不明白的核心问题。
PART 06
这才是具身智能的自然交互
人类给别人指路,从来不是长篇大论,而是手指一下。
Point-VLA把这件事搬到机器人身上:人类用手指目标,MLLM自动转成框 ;人在GUI上随手画个框,配两个字指令,机器人立刻理解: 就这个,执行这项操作 。
它绕过了自然语言的模糊性,用最直观的视觉信号,填补了VLA最后一道空间对齐鸿沟。
团队在论文结尾写道:
Point-VLA证明, 显式视觉锚定,是实用、即插即用的VLA接口 。它在解决文本歧义的同时,提升稳健性、泛化性,甚至反向增强纯文本能力。
从听文字猜意图到看框直接干活 ,机器人的交互方式,正在被这一个小小的视觉框彻底改写。
论文地址:
https://arxiv.org/pdf/2512.18933
项目地址:
https://yuhang-harry.github.io/Point-VLA/