


中国团队率先实现视频学习训练机器人操作技能

爱力方
当特斯拉宣布Optimus机器人将放弃传统动作捕捉方案,转而利用员工日常操作视频进行训练时,这一决策犹如投入平静湖面的巨石,在业界引发广泛反响,同时也标志着具身智能的学习范式正在经历一场深刻变革。
无独有偶,李飞飞团队和Figure AI也都提出了通过人类视频学习日常技能的机器人训练方法。
但鲜为人知的是,这项底层技术早已被一个中国团队率先实现:今年年初,跨维智能发布的YOTO(You Only Teach Once)双臂协同操作技术框架,仅用30秒短视频就能将双机械臂训练成"米其林帮厨",无需遥操作、无需真机数据采集,展现出卓越的泛化迁移能力。这一前沿技术框架证明,仅凭单条双目纯视觉人类视频就能让双臂机器人零示教复现复杂长程操作,相关论文已被2025年初的机器人顶会RSS收录。视频学习的竞赛,其实早已在中国按下启动键。
这种"所见即所得"的学习模式,极大地拓展了机器人与环境交互的可能性边界。
近期,该团队再次发布升级版视频学习框架,双臂机器人不仅能完成精准的双臂长程任务,还能自主识别任务对象状态。无论是倒扣的透明碗、塑料框,还是随机抛出的各种水瓶,在面对干扰时都能流畅完成任务,成功率高达95%。这一技术已快速迁移到不同机器人平台,展现出智能涌现的巨大潜力。
1.视频学习的本质究竟是什么?真能让机器人"一看就会"吗?
视频学习的核心在于将人类在视频中展现的时空行为模式和语义意图转化为机器人可执行的操作策略:视频提供了丰富的自然演示,包括空间布局、手物交互、动作分段和语义上下文等信息。这些信息若能可靠提取和对齐,将大幅减少对人工示教或昂贵遥操作数据的依赖,实现规模化技能获取(关于从互联网视频扩展机器人学习的概念与综述,请参见近年来的Survey [2])。

图源自网络然而,视频学习存在几个固有缺陷:•具身本体差异:人类演示的运动学/动力学特性与机器人平台不匹配,直接复制会导致失败;
•物理交互缺失:纯视觉信号无法提供接触力、摩擦等物理量,导致真实接触时策略不稳定;
•感知噪声与语义歧义:遮挡、视角差异、物体多样性等因素使得从稀疏无标签视频中学习可执行动作面临高噪声挑战;
•长时序一致性与阶段化策略学习困难:如何从连续视频中提取语义分段(关键帧)并保持时空一致性。
这些问题也是近期多项具身操作研究的关注焦点,例如多个团队正在探索使用大规模视频预训练或无标签视频蒸馏来获得通用视觉-动作表示(如Latent Action Pretraining [3]/VidBot [4]等),旨在实现"从互联网视频直接学习可跨形态的机器人控制"。
在跨维智能的视频学习框架中,研究团队通过一系列创新设计,有效缓解了上述固有缺陷。

为解决具身本体差异和长时序一致性问题,团队不直接回归密集连续动作,而是将人手演示简化为语义化关键帧序列和运动掩码(motion mask)。这种离散化方法既能去噪又保留了操作要点,使不同臂型间的运动重定向(retargeting)更加稳定和易于校正。
针对物理交互信息缺失,团队采用示教驱动的快速示例增殖(auto-rollout + 3D几何变换),在真实机器人上生成多样化、可验证的训练样本,建立视觉与真实执行间的可靠对照。为提高感知鲁棒性和实现闭环抗扰,YOTO++引入了轻量级视觉对齐模块(pre-grasp alignment)(YOTO++ [5]),利用2D掩码的几何中心和二阶矩估计平移与朝向偏差,通过手眼标定映射到机器人坐标系,在初始抓取阶段实施高频闭环校正,显著提升了动态扰动下的抓取和执行成功率。
该视频学习框架与当前"用大模型做语义引导"的趋势形成互补(如李飞飞团队提出的关联关键点ReKep [6]、操作模态链CoM [7]等):团队使用多模态大模型(VLM)处理物体语义/掩膜/语言提示的稳健感知,而关键帧+扩散策略(BiDP)负责动作表示与生成,二者在"语义先导、动作可执行"的路径上协同工作。
实际上,近年来业界的动向(以Google和Tesla为例)也反映了这两条互补路线:一方面,Google等团队尝试将大规模多模态/语言模型与机器人控制结合(如RT-1 [8]/Gemini Robotics [9]),强调使用语言和视觉作为条件训练统一控制器以提升跨任务泛化;另一方面,工业阵营(如Tesla的Optimus团队)正将训练重心从昂贵的动作捕捉/遥操作转向大规模视觉驱动数据采集,希望通过海量视频或员工演示实现更广的训练覆盖面。这两条路线都显示出"用大规模视频与强语义模型扩大样本池"的潜力,但也暴露了纯视觉预训练在物理可靠性和跨具身执行方面的局限性。
另一个视角是重新审视"数据金字塔"概念:团队将视频模仿学习的样本来源分为三层:底层是海量互联网视频,特点是无标签、分布多样、语义丰富;中间层是半结构化的人类演示数据/仿真合成数据,通常具有较好的视角和场景一致性,但与机器人本体仍存在差异;顶层是经过验证的真机数据/遥操作数据,包含精确动作和物理反馈。这些数据的获取难度逐层递增,现存数量也逐渐减少。

跨维智能视频学习框架的设计理念是:利用底层和中层视频快速获取语义与时空先验(高效、直观、可解释),通过自动增殖和少量真实回放快速生成有标签训练对照,形成"少样本—可扩展—可验证"的闭环体系。这种"少样本视频模仿"具有直观(直接来自人类演示)、高效(减少昂贵采集)、可扩展(通过几何变换/合成扩增)与可解释(关键帧/语义标签易于人工审查)等优点,在工程实践中更具可行性。跨维智能研究团队在视频学习方向展示了领先的技术成果:•基于关键帧与运动掩码的表示方法,在跨臂型迁移中显著提高执行成功率;
•结合真实auto-rollout与几何扩增的数据增殖策略,可在无需大量人工标注的情况下快速生成数千条可验证轨迹用于训练鲁棒策略;
•视觉对齐的闭环预抓取方法,在多次动态扰动试验中显著提升抓取成功率,缩小抓取到完成任务间的性能差距(部分解决了最脆弱的接触前阶段问题);
•将VLM用作语义/掩膜增强器与BiDP用作动作生成器的组合,在工具使用等长时序任务中保持良好的时空一致性和泛化能力;
该视频学习框架既契合大规模视频预训练的长期发展方向,又通过工程化的表示、数据增殖与闭环对齐手段,弥补了纯视频学习在"物理可执行性"方面的不足,为可泛化的具身操作提供了一条务实可行的技术路径。
2.视频学习结合Sim2Real技术:机器人高鲁棒、泛化的新曙光这一创新性视频学习框架通过极少的真实数据样本,结合Sim2Real高效数据增殖,使VLA模型具备极强的泛化性能。在家居服务场景中,机器人仅需一次视频输入就能达到≥95%的任务成功率。
视频显示,双臂机器人通过"头部"的双目纯视觉传感器识别不同瓶子的位置和状态,能快速扶正随机抛出的各种状态瓶子。即使面对未见过的瓶子,机器人仍展现出强大的抗干扰和泛化能力,在连续作业中达到95%的任务成功率,率先通过"连续20次一镜到底"压力测试。
同时,机器人在面对连续随机干扰时,能自主识别哪只"手"距离瓶子更近,并使用更接近操作对象的手臂完成任务。这项技术不仅实现了任意未知物体、未知状态和连续扰动下的技能泛化,还实现了新技能的零真机快速生成和跨平台平滑迁移,展现出VLA模型智能化、高鲁棒、跨场景和规模化部署的巨大潜力。
研究团队以视频学习框架为核心,针对动态环境提出了这套高效且鲁棒的模型适配框架。
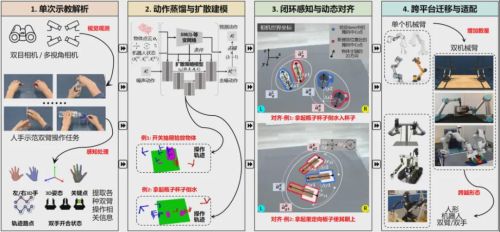
该框架利用视觉语言大模型(VLMs)的跨模态理解与推理能力,从单次示教视频中提取关键帧并生成语义化动作表示,显著降低数据需求;同时建立"感知—语义—动作"统一表征,将领域知识嵌入视觉、语言与动作空间,实现跨任务、跨环境泛化。
为提升抗干扰与一致性,团队引入Sim2Real数据扩增与增量适配机制,提出"闭环抓取+开环执行"混合控制范式,并设计基于图像矩的轻量化视觉对齐算法替代传统6D姿态估计,确保高动态场景下的实时性能。
此外,双臂扩散策略模型(BiDP)结合语义条件学习,对长时序、多阶段动作(如工具使用)进行建模,保持时空一致性。实验在单臂、对侧双臂、同侧双臂及人形双臂等多种平台上验证了框架的跨形态可迁移性,突破了传统模仿学习对大规模示教和单一任务环境的依赖。
3.具身智能或将迈入"全民共创"新时代从厨房到便利店、从产线到无菌实验室,一旦双臂机器人摆脱"千次示教、万元治具"的束缚,具备"看完就会"的协同能力,"示范一次"将变成"遍地可用"的新标准,这将为机器人打开千行百业的大门。
这种技术演进正在重塑工业智能化发展路径。从跨维智能让机器人理解互联网视频,到特斯拉用头盔摄像头记录员工动作,具身智能正逐步摆脱对专业数据采集的依赖,迈向"全民共创"的新时代。跨维智能视频学习框架的成功实践充分证明,视频不再仅仅是数据载体,更成为了机器人理解世界的"通用语言"。随着多视角融合、开放域识别等技术的日益成熟,未来工厂里的机器人或许能通过观看数十年前的工艺视频重新掌握失传技艺;家庭服务机器人也可实时学习网红菜谱。这种跨越时空的知识传递能力,正是视频学习赋予具身智能的独特魅力。
Reference:
[1] You Only Teach Once: Learn One-Shot Bimanual Robotic Manipulation from Video Demonstrations, RSS'2025 https://arxiv.org/abs/2501.14208[2] Towards Generalist Robot Learning from Internet Video: A Survey, JAIR'2025 https://arxiv.org/abs/2404.19664
[3] Latent Action Pretraining from Videos, ICLR'2025 https://arxiv.org/abs/2410.11758[4] VidBot: Learning Generalizable 3D Actions from In-the-Wild 2D Human Videos for Zero-Shot Robotic Manipulation, CVPR'2025 https://arxiv.org/abs/2503.07135
[5] YOTO++: Learning Long-Horizon Closed-Loop Bimanual Manipulation from One-Shot Human Video Demonstrations, https://hnuzhy.github.io/projects/YOTOPlus/[6] ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation, CoRL'2025 https://arxiv.org/abs/2409.01652
[7] Chain-of-Modality: Learning Manipulation Programs from Multimodal Human Videos with Vision-Language-Models, ICRA'2025 https://arxiv.org/abs/2504.13351[8] RT-1: Robotics Transformer for Real-World Control at Scale, RSS'2023 https://arxiv.org/abs/2212.06817
[9] Gemini Robotics: Bringing AI into the Physical World, https://arxiv.org/abs/2503.20020













