资讯

上海新增11款生成式AI服务过审 累计达149款
上海市网信办公布最新一批生成式人工智能服务备案信息,本月新增11款,全市累计备案总数已达149款。此举体现了上海在推动AI创新与规范应用方面的领先地位,其中顶尖科研机构的模型表现突出,监管细节也进一步明确,涵盖独立模型及调用备案模型能力的相关服务。

两会政策预期升温 三月A股走向引关注
本文分析了A股市场在两会政策预期升温背景下的表现,指出资源股强势、科技股回调的市场分化特征。文章探讨了杠杆资金回暖、板块轮动加快等现象,并预测3月行情可能呈现“先扬后抑”走势,建议投资者关注政策导向、业绩验证及海外风险,均衡配置以应对市场震荡。

地震预警与地震波大模型入选防震减灾十大科技进展
2025年公众关注的防震减灾十大科技进展揭晓,涵盖地震预警技术应用、全球首个亿级参数量地震波大模型开放使用、'张衡一号'02星发射、海底地震观测站建设等关键成果。这些进展显著提升了地震监测预警、科学研究和灾害防御能力,为保护人民生命财产安全和推动行业发展提供了重要科技支撑。

谷歌与OpenAI员工联名声援Anthropic,坚守AI伦理拒当战争工具
本文报道了Anthropic公司因拒绝美国五角大楼无限制使用其AI技术的要求而面临封杀威胁,引发谷歌与OpenAI员工联名支持的事件。文章揭示了科技公司员工团结抵制AI技术被用于大规模监控和自主武器的伦理立场,并分析了硅谷巨头在军方合作与社会责任之间的复杂博弈。

英伟达联手Groq打造定制推理芯片 OpenAI入伙或重塑AI竞赛格局
英伟达联手Groq推出定制化AI推理处理器,专为OpenAI等顶级开发者设计,旨在实现推理性能的跨越式提升。这一战略转型标志着英伟达从通用GPU供应商转向深度定制系统架构商,以应对行业自研潮,并成功稳住OpenAI等核心客户。此举或将重塑AI竞赛格局,推动行业进入以推理效率为核心的新阶段。

Anthropic遭封杀之际 OpenAI拿下五角大楼订单
本文报道了AI行业戏剧性的一周:OpenAI与美国国防部达成协议,将在其机密网络中部署AI模型;而竞争对手Anthropic则因谈判破裂,被特朗普政府列入黑名单并禁止联邦机构使用。文章分析了双方在AI安全原则上的立场差异,以及国防部最终选择OpenAI的原因,揭示了AI企业与政府合作中的伦理与商业博弈。

特朗普下令联邦机构停用克劳德AI模型
美国总统特朗普于2月27日下令所有联邦机构立即停止使用安特罗匹克公司开发的AI模型“克劳德”,并设定六个月过渡期。此举源于该公司拒绝国防部要求取消模型使用约束条件,特朗普批评其行为危及国家安全和士兵安全。国防部随后将该公司列入供应链风险名单,计划在过渡期内完成技术替换。

英伟达联手Groq发布定制芯片 OpenAI成首位客户
英伟达计划在GTC开发者大会上发布一款整合Groq技术的新型推理芯片,旨在提升AI任务响应效率并巩固市场地位。OpenAI将成为首批最大客户之一,用于升级其Codex工具。此举标志着AI算力竞争进入注重效率与性价比的新阶段。
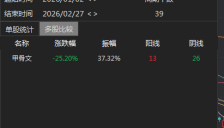
对冲基金抄底软件股 抛售潮或已触底
文章分析了2026年初美股软件板块因AI技术冲击、市场恐慌和高估值压力而大幅回调的现象,指出对冲基金和散户已开始逢低买入。文章探讨了AI对软件行业商业模式的深层影响,并引用基金经理和机构观点,认为市场过度悲观,部分优质软件股已具备投资价值。

三场风暴席卷Anthropic:五角大楼紧盯,软件业警惕,出版业维权
本文报道了AI独角兽Anthropic近期陷入的多重争议:因拒绝五角大楼的军事应用要求,被特朗普政府封杀并列为国家安全风险;在资本市场频繁发布新品冲击软件行业,同时自身却面临巨额版权侵权诉讼;公司内部安全政策出现松动,引发对AI伦理的担忧。文章揭示了这家估值3800亿美元的公司如何在政治、商业和伦理风暴中挣扎。

三星AI家电引领健康生活新风尚
本文介绍了三星AI神系列家电如何通过AI科技为春季健康生活提供全方位解决方案。从AI神黑钻热泵洗烘旗舰和衣物护理机实现衣物洗烘护一站式健康管理,到AI神冰箱9系通过智能识别和保鲜技术保障饮食新鲜与科学膳食,帮助用户轻松应对换季健康挑战,让健康融入日常穿衣与饮食的每一个细节。

宝马德国工厂引入人形机器人 试点接管最累装配工序
宝马集团宣布在德国莱比锡工厂启动人形机器人试点项目,首次将物理人工智能引入欧洲汽车生产线。该项目旨在将人形机器人技术融入现有量产流程,用于装配线和电动车电池制造等体力消耗大的工序,以减轻员工负担、提升效率。宝马此前已在美国工厂成功试点,反映其正押注人形机器人市场的增长潜力,未来可能将更多生产环节转移到内部完成。
Meta打破英伟达垄断,签署数百亿美元大单租用谷歌TPU自研AI模型
Meta与谷歌达成数十亿美元协议,租用谷歌TPU开发AI模型,挑战英伟达在AI芯片市场的垄断地位。此举旨在缓解算力焦虑并探索GPU替代方案,可能推动芯片价格下降,加速行业多元化竞争。
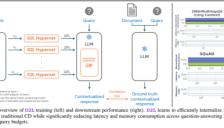
Sakana AI发布超轻量插件,实现大模型快速处理海量文档
Sakana AI推出的Text-to-LoRA和Doc-to-LoRA技术,通过超网络架构让大模型无需重新训练,即可在不到一秒内处理超长文档或学习新任务。D2L技术将处理12.8万Token文档的内存需求从12GB降至50MB,速度提升百倍,并支持跨模态应用,极大降低了AI定制门槛。
OpenAI与亚马逊战略合作 共建AI智能体新生态
OpenAI与亚马逊达成500亿美元战略合作,共同开发有状态运行环境,让AI具备记忆和连续工作能力。双方将在算力、平台分发和定制模型方面深度整合,旨在推动AI智能体技术的大规模商业化应用,定义行业新标准。