资讯

斯坦福李飞飞团队提出新框架 机器人可从错误中学习
斯坦福李飞飞团队提出全新 Reflective Test-Time Planning 框架,赋予机器人类人的反思能力,使其能从错误中学习并优化决策。该框架通过三重反思机制,显著提升任务成功率,展现出强大的实际应用潜力。

西南科大爬壁机器人实现全角度翻转突破
本文介绍西南科技大学研发的一款翻转连续体爬壁机器人,其灵感来源于象鼻子和尺蠖结构,具备387°超强弯折能力及多模态运动性能。该机器人采用电磁吸附技术,适应多种复杂工业场景,具有重要的学术价值与工程应用潜力。

Science子刊突破:机器人装指尖 平衡木2.4秒碾压人类
香港城市大学与南方科技大学联合研发的TAP触觉传感器让机器人首次具备类似人类的指尖触觉能力,在平衡木挑战中以2.4秒完胜人类的6.5秒。这项发表在《Science Advances》的研究展示了机器人如何通过实时扭矩反馈实现精准操作,包括切萝卜等精细任务,标志着机器人触觉技术的重大突破。
鹿明FastUMI Pro数据超市上线 覆盖10大场景40余种任务
鹿明机器人正式上线FastUMI Pro数据超市,将具身智能操作数据以“标准商品”方式明码标价、在线下单。数据覆盖10大场景、40+任务,提供结构化标签与透明定价,并计划推出定制数据服务。依托统一数采设备与SOP,数据格式一致、可用于多类机器人模型训练,降低高质量真实数据获取成本。

亦庄机器人携手机械伊甸 首创全球双4S融合模式
全球首个“双4S融合模式”在北京波士瑞达奔驰4S店成功落地,机器人4S店机械伊甸入驻汽车展厅,实现机器人展示、销售、服务与信息反馈的全生命周期服务。这一创新模式由北京亦庄RobotMall资源赋能,连接机器人厂商与传统渠道,为传统行业注入智能化活力,同时为机器人产业提供可复制的落地路径,提升客户体验并开辟新的盈利增长点。

东京大学飞行器实现92.5%成功率完成复杂空间穿越
东京大学研究团队开发了一种分层轨迹规划框架,使多连杆飞行机器人能够以92.5%的成功率自主穿越复杂狭小空间。该技术解决了可变形态机器人在高维空间中的路径规划难题,通过结合全局引导和局部优化,确保飞行过程既安全又可控,为灾难搜救和工业巡检等应用提供了新可能。

港城大港中文团队研发微型机器人实现“上天遁地”
香港城市大学与香港中文大学合作研发的RoboIMP微型机器人突破尺度效应限制,通过冲击驱动和振荡流化技术,在复杂介质中实现持续强力输出和自由穿行,为医疗和工业应用带来新突破。

Notion联手国产AI推出开源模型 重塑工作流主打性价比
Notion宣布引入首个开源权重模型MiniMax M2.5,打破闭源模型垄断,为全球用户提供高性价比AI选择。该模型针对智能体工作流优化,在文档处理、任务自动化等场景中表现卓越,成本远低于闭源模型,标志着国产大模型进入全球主流生产力工具核心。

DeepSeek V4即将发布 多模态模型或重塑AI格局
DeepSeek即将发布全新多模态模型V4,具备图像、视频和文本生成能力,并全面支持国产算力。同时推出的V4 Lite测试版拥有2000亿参数和100万tokens上下文窗口,原生多模态架构显著提升处理能力。这一系列技术突破将加速AI与本土芯片的融合,为人工智能领域带来新的发展动力。

再携手!清华陈建宇×斯坦福Chelsea团队发布VLAW,世界模型×VLA协同进化
清华陈建宇团队与斯坦福Chelsea Finn团队联合发布VLAW框架,首次实现视觉语言动作策略与世界模型的协同进化。该框架通过真实交互数据提升世界模型的物理保真度,同时利用高质量虚拟数据强化VLA策略,解决了现有世界模型盲目乐观和物理模拟不准确的难题,为具身智能的发展提供了新思路。

浙大团队突破低压DEAs人造肌肉技术 解决介电弹性体高压瓶颈
浙江大学团队在《Science Robotics》发表突破性研究,成功开发出低压高输出介电弹性体执行器(LVHO-DEA),仅需200伏电压即可驱动,解决了传统介电弹性体人造肌肉需要千伏高压的难题。该技术通过材料创新和工艺优化,实现了超越自然肌肉的能量密度和功率密度,并应用于无系绳软体机器人,为可穿戴设备和柔性机器人领域带来重要进展。
DeepSeek V4即将发布 多模态模型提升AI智能生成
DeepSeek即将发布全新的多模态大语言模型V4,原生支持图片、视频和文本的AI生成能力。该模型不仅填补了国内低成本开源模型的市场空白,还通过与华为、寒武纪合作进行硬件优化,推动本土半导体发展。V4的发布将极大拓展AI在创作、广告和教育等领域的应用潜力,助力中国在全球AI领域的竞争力提升。
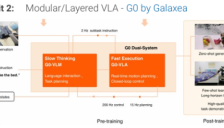
人形机器人智能大脑进化路径
文章深入探讨了人形机器人“大脑”即核心AI模型的演进路径,分析了当前主流的视觉语言动作模型的优势与局限,并揭示了数据稀缺与边缘算力不足两大核心挑战。报告指出,产业正通过提升仿真质量、建设数据工厂、融合跨本体数据等多重策略寻求突破,并预测未来竞争将演变为一场规模游戏,结构性优势将决定企业间的差距。

谷歌发布Nano Banana 2图像AI模型 告别中文乱码 画质直达4K
谷歌发布新一代图像生成模型Nano Banana2,基于Gemini3.1Flash Image架构,显著提升理解能力和响应速度。该模型重点修复了中文字符乱码、语义混乱等顽疾,支持生成清晰中文文本,画质从2K提升至4K,增强角色一致性和复杂场景处理能力,将整合至Gemini、Google AI Studio等多款产品中。

大模型赋能化工厂安全 AI技术重构防护体系登顶刊
微筑科技联合产学研团队在权威期刊EAAI发表基于扩散模型的化工安全智能监控框架研究。该技术通过AI生成训练数据,结合多模态模型与先进检测算法,精准识别工人危险行为与环境隐患,检测准确率最高达98.1%,有效解决化工安全监控中数据稀缺与误判难题,为工业安全生产提供智能化解决方案。