资讯

小米发布首代机器人 VLA 大模型,突破物理智能延迟瓶颈
小米开源首代机器人VLA大模型Xiaomi-Robotics-0,拥有47亿参数,采用创新的MoT混合架构,通过视觉语言大脑和动作执行小脑协同工作,有效解决了现有模型因推理延迟导致的动作迟缓问题。该模型在消费级显卡上实现实时推理,并在多项仿真测试中刷新SOTA成绩,展现出卓越的手眼协调和物理泛化能力。小米全面开放技术资源,推动具身智能领域发展。

Mistral 发布全新语音转文字 AI 模型,主打极致低延迟
Mistral AI发布两款全新语音转文字模型Voxtral Mini Transcribe V2和Voxtral Realtime,主打极致低延迟与高性价比。实时模型延迟最低可配置为200毫秒,支持本地部署保障隐私;批量处理模型在词错率基准测试中表现优异,API价格低至每分钟0.003美元。两款模型均原生支持中文、英语等13种语言,适用于虚拟助手、呼叫中心等多种商业场景。

机械臂精度提升:双编码器破解回差问题
本文深入探讨了机械臂控制中回差问题的解决方案,详细分析了单闭环控制和双闭环控制(串级PID)的优缺点。重点阐述了如何利用双编码器(电机端和关节端)设计控制算法,实现高精度定位并抑制振荡,提升系统动态性能。文章还介绍了前馈+反馈控制变体以及回差测试的重要性,为机器人精密控制提供了实用指导。
具身智能取得新进展 达摩院开源RynnBrain登顶16项全球榜单
阿里巴巴达摩院开源了具身智能大脑基础模型RynnBrain,包含7个全系列模型,其中30B MoE规模模型首次赋予机器人时空记忆与空间推理能力,显著提升智能交互水平。该模型在16项全球评测榜单中刷新纪录,超越国际顶尖模型,旨在降低研发门槛,加速机器人在工业及服务场景的应用。
神秘AI模型Pony Alpha曝光 免费高性能或为GLM-5伪装版
OpenRouter平台悄然上线的神秘AI模型“Pony Alpha”凭借免费使用、高性能表现引发关注。文章深入剖析其惊人的编码与推理能力、200K上下文窗口支持,并探讨其疑似GLM-5伪装版的身份谜团,同时提醒用户注意数据隐私风险。
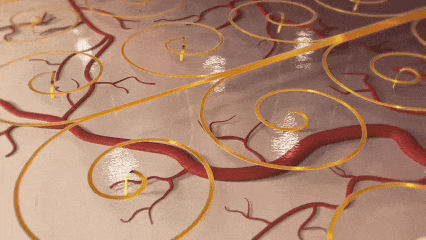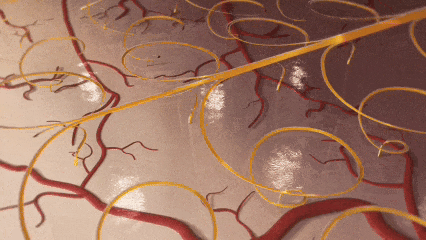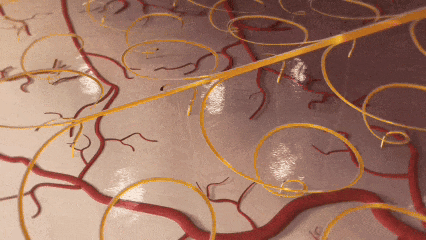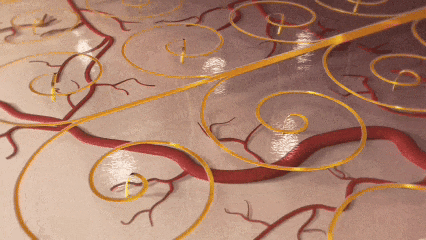
中国团队突破脑机接口技术瓶颈
中国科研团队在《Nature Electronics》发表突破性成果,成功研制出可拉伸柔性电极,解决了侵入式脑机接口中电极易移位、脱出的世界难题。该技术受剪纸艺术启发,通过可重构螺旋线阵列实现与大脑动态共融,在猕猴实验中稳定采集1024通道信号,为运动功能障碍患者的意念操控设备奠定基础。

LaST₀:赋予机器人物理直觉,摆脱语言依赖像人类思考动作
LaST₀框架让机器人摆脱语言依赖,通过隐空间思维链直接进行物理模拟推演,实现高效连贯的动作执行。该技术采用双专家系统协同工作,显著提升任务成功率和推理速度,在多种机器人形态上展现出卓越的泛化能力。

LaST₀弃用语言推理 为机器人植入物理直觉大脑
本文介绍了LaST₀框架如何通过隐空间思维链让机器人摆脱语言推理的局限,直接进行物理模拟推演。该技术采用双专家系统实现快慢思考协同,在多项任务中显著提升成功率和推理速度,展现出卓越的时空理解能力和跨机器人形态的泛化潜力。
瑞士团队研发出可自主爬行的机械手
瑞士研究团队开发出革命性的可拆卸机械手,能够自主爬行并执行抓取任务。这款机械手采用对称可逆设计,每个手指都能双向弯曲,实现多对象抓取和形态自由切换。它不仅能完成33类人类抓取动作,还能在爬行中携带物体,为灾难救援、仓储物流等领域带来创新解决方案。

苹果论文再掀波澜 Qwen3-Coder特调后UI生成能力超越GPT5
苹果UICoder团队最新研究论文展示了如何通过专家级反馈微调开源模型Qwen3-Coder,在UI生成领域超越GPT-5。该研究利用21位资深设计师的深度逻辑注释构建奖励模型,仅用181个高质量草图反馈就实现了性能突破,揭示了专家反馈在AI训练中的关键作用,并探讨了审美主观性与AI设计工具的未来潜力。
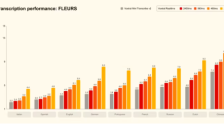
Mistral AI发布Voxtral Transcribe 2语音模型,中文实时转录延迟低于0.2秒
Mistral AI发布Voxtral Transcribe 2语音模型系列,包括Voxtral Realtime实时转录模型和Voxtral Mini Transcribe V2批量处理模型。Realtime模型延迟低于0.2秒,支持音频即时转录,并已开源权重;Mini版在准确率上超越GPT-4o mini等竞品,支持3小时长音频处理。两款模型均支持中文等13种语言,定价具有竞争力,适用于实时对话、同声传译及批量转录场景。

上海AI实验室开源全球最大科学多模态模型Intern-S1-Pro
上海人工智能实验室开源了全球最大的科学多模态模型Intern-S1-Pro,拥有万亿参数,基于创新的SAGE架构和混合专家技术,在数理推理和科研任务中达到国际领先水平,标志着从模型架构到国产算力自主技术的完整突破。

昆仑天工发布Skywork桌面版 Windows电脑可雇佣AI员工
昆仑天工发布Skywork桌面版,将AI Agent能力从网页对话升级为系统级主动协作。该应用支持本地化执行,可直接读取处理电脑中的各类文件,并集成Claude4.5与Gemini3Pro双模型,提供超过100个办公技能,通过本地虚拟机保障数据安全,为Windows用户带来高效的“AI员工”体验。

浙大团队研发仿生飞行机器人 可抓握栖息灵活运载
浙江大学团队研发出仿生飞行机器人HI-ARM,将人手的灵巧抓取与无人机的敏捷飞行深度融合,实现了空中自主抓取、开门、栖息和运输等功能。这款仅手掌大小的机器人具备5自由度变形能力,能在复杂环境中完成多种任务,展示了空中操作机器人的巨大潜力。


Claude 5发布:Anthropic推出代号Fennec编程模型,行业格局或将重塑
Anthropic即将发布代号为Fennec的Claude Sonnet5模型,这款被誉为史上最强编程模型在性能上超越旗舰Opus4.5,定价降低50%,并拥有100万token上下文窗口。其突破性的蜂群开发模式能自动组织多智能体协作,在SWE-Bench测试中得分超过80%,将彻底改变编程AI的格局。